Human language, Word meaning
usage (application)
- machine translation
- search
- LLM
- image→text explain
meaning
- 추상적인 개념을 어떻게 표현해야하나
- symbolize 가능할까?
WordNet
- 동의어(synonym), 상위어(hypernyms)
- 각각의 단어가 어떤 관계인지 mapping
- 한번 구축하면 바꾸기가 어려움
- 주관적인 해석에 따라 다름
Representing words as discrete symbols
one-hot vector1로 단어의 의미를 표현한다
 vector dimension은 vocabulary 개수
vector dimension은 vocabulary 개수
문제 없냐?
Seattle motel , Seattle hotel의 유사성을 찾기가 어려움
- 두개의 벡터는 orthogonal
- no natural notion of similarity for one-hot vectors
그럼 두개의 벡터를 어떻게 의미상으로 유사하게 표현할 수 있을까
Representing words by their context
- Distributional semantics
- 동일한 단어의 근처에 있는 context word로 의미를 표현한다
Word vectors
one-hot 이 아닌 dense vector로 표현
- 유사한 단어들을 근처에 위치하게 하기 위함


- word embedding, word representation으로도 불림
Word2vec
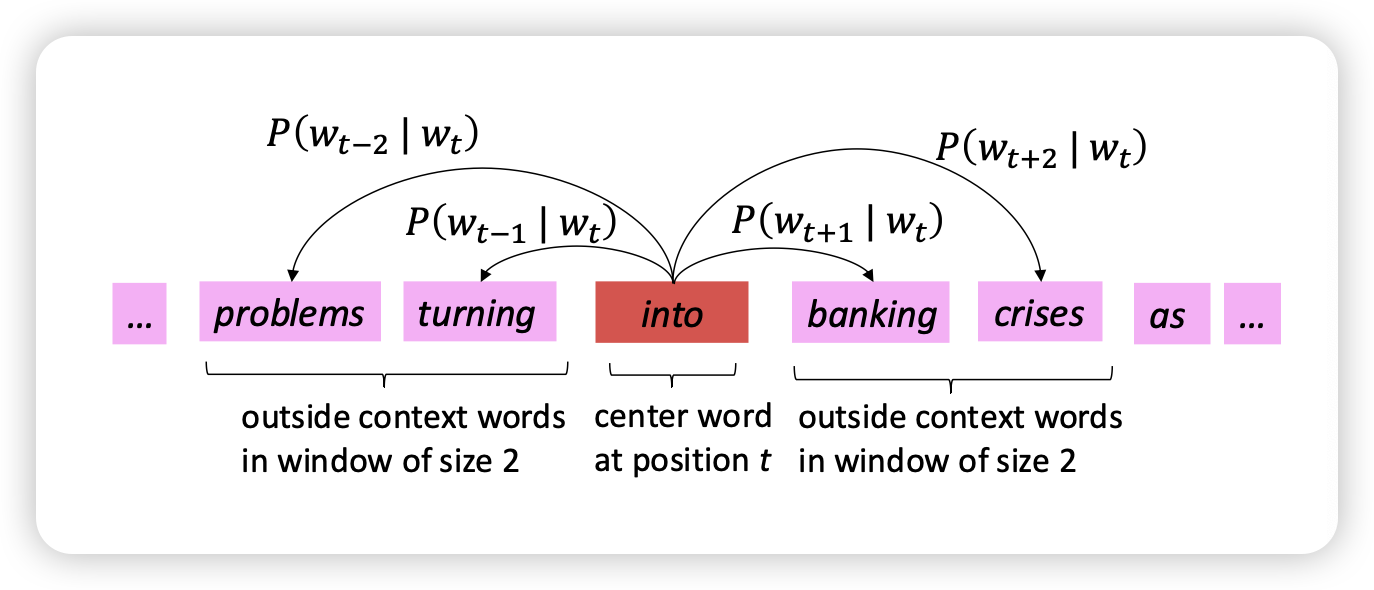
- word의 앞뒤 단어가 나올 확률을 계산
likelihood
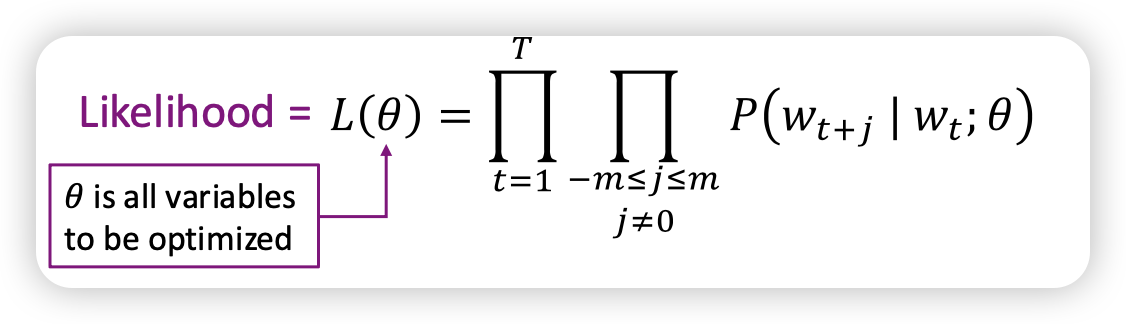 objective function (loss function)
objective function (loss function)
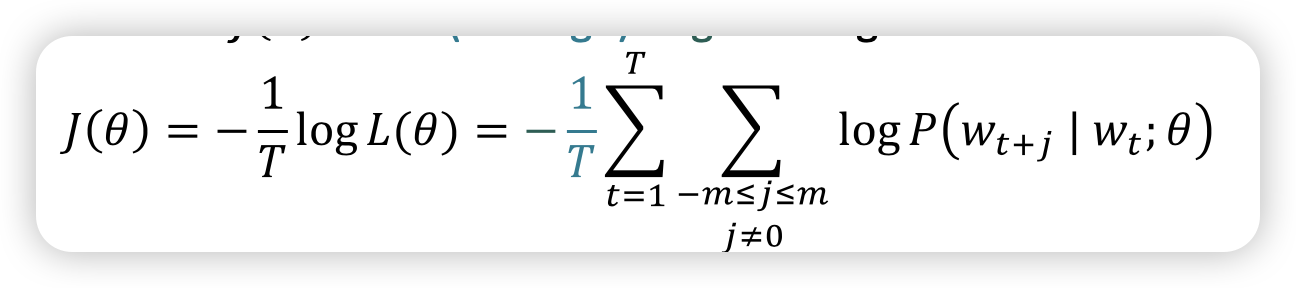
𝑃(𝑤𝑡+𝑗 | 𝑤𝑡; 𝜃) 2는 어떻게 구하나요?
prediction function
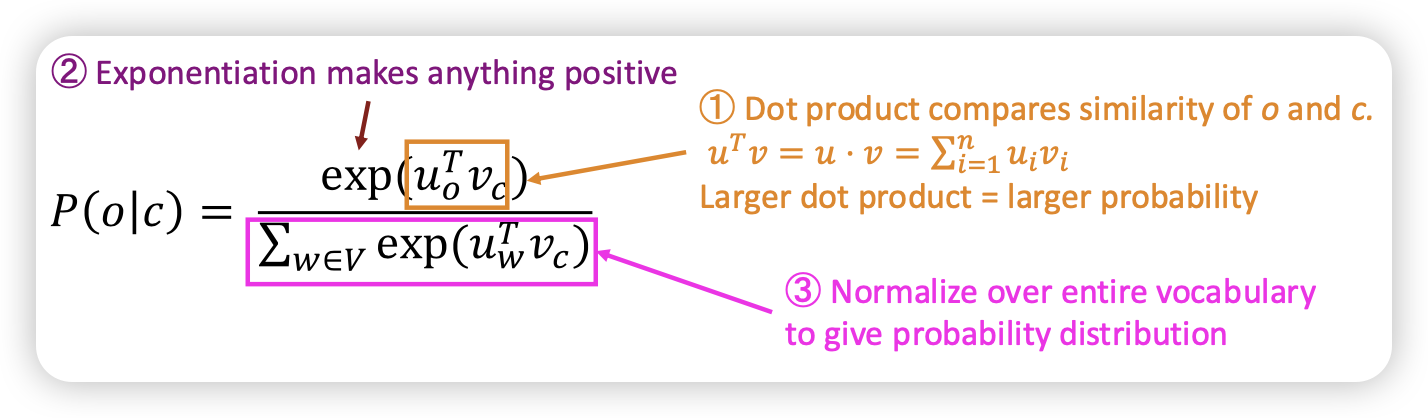
- softmax function을 통해 구현
- o = 타겟 단어 (output word)
- c = 문맥 단어 (context word)
- u_o = 타겟 단어의 벡터
- v_c = 문맥 단어의 벡터
- u_w = 단어 w의 벡터 (어휘 집합 V에 속한 모든 단어에 대해 계산)
왜 softmax를 쓰나요??
Goal
- To train a model, we gradually adjust parameters to minimize a loss
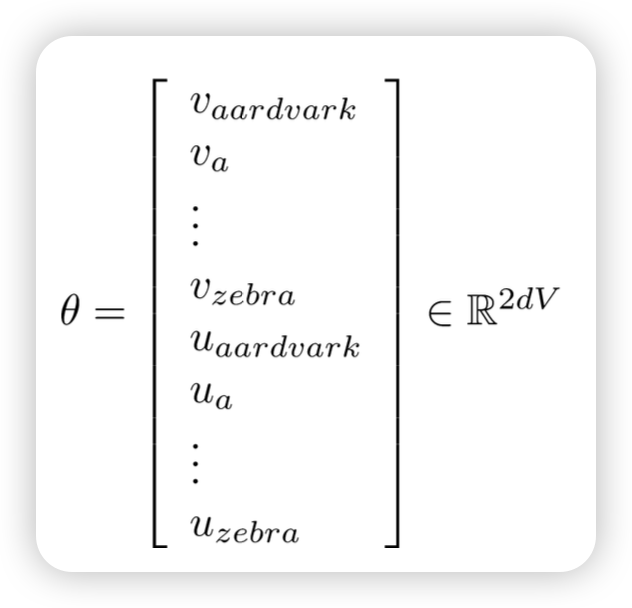
- Recall: 𝜃 represents all the model parameters, in one long vector
Optimization: Gradient Descent
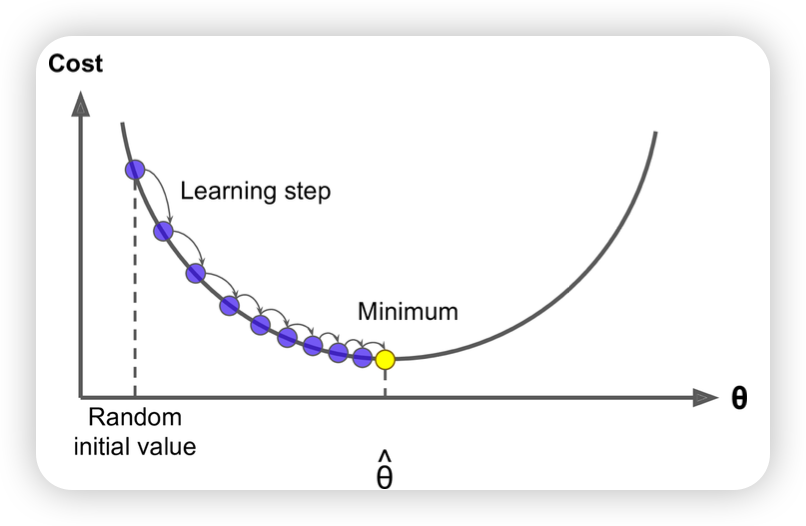
- 초기 랜덤 값 시작
- 기울기가 0이 되는 곳으로 이동하게 함
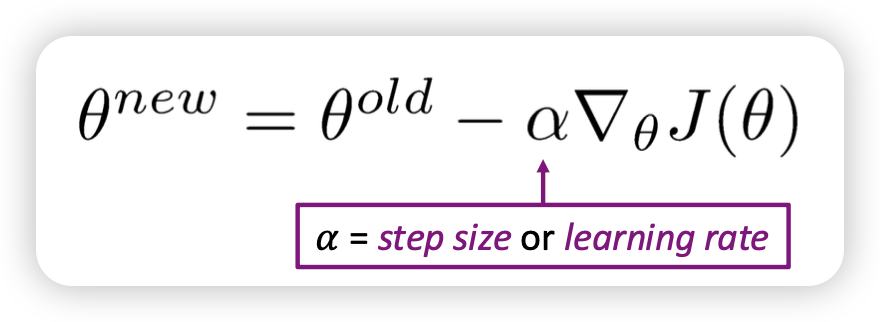 Stochastic Gradient Descent
Stochastic Gradient Descent - corpus 내 모든 단어에 대해서 loss가 최소로 하다보니 너무 많음
- mini batch를 써보자!
- 한번에 전체가 아니라, chunk를 짤라서 하자
- 연산량을 줄이기도 하면서, local optimize에서 탈출 가능
gradient를 구해봅시당! ㅎㅎ 시험 나올수도 있어용