recap
- (word vector) 같은 context를 가지는 center word가 어디에 배치되어야 할까?
그럼 sequence(순서)는 고려하지 않나여? 네 안해요 context window 내에 있는 것만 고려해요
- Optimization (gradient descent) 𝐽 (𝜃) 을 minimize 하는 것을 목표로 함
하지만 모든 corpus에 대해서는 만족하는 optimal을 구하기 어려움 → 때문에 sample_window(mini batch)를 통해서 구함 → Stochastic gradient descent (SGD)
Skip grams
주어진 center word를 통해서 바깥 context를 예측함
Continuous Bag of Words (CBOW)
context를 통해 center word 예측
→ 최근 Bert 모델
왜 그럼 처음부터 CBOW 안썻어요? 연산량이 너무 많아서 loss function 구하기 힘들었음
negative sampling

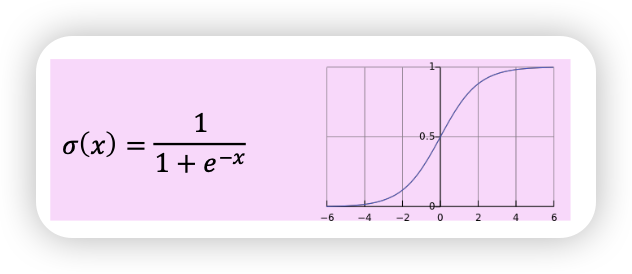
- 기존 softmax가 너무 연산량이 많음 → negative sampling 사용
- 실제 문맥 단어 o가 등장할 확률을 최대화하고,
- 무작위로 샘플링한(negative) 단어들이 등장하지 않을 확률을 최대화합니다.
즉, “실제 단어는 높은 점수를 주고, 무작위로 뽑은 단어들은 낮은 점수를 주는 방향으로 학습” 합니다.
네거티브 샘플 w 를 선택할 때 단순히 균등 분포에서 샘플링하면 자주 등장하는 단어들(“the”, “is” 같은 stop words)이 지나치게 많이 뽑히는 문제가 발생합니다. 이를 해결하기 위해 빈도 기반 샘플링 방법을 사용합니다.
어 그럼 SGD + negative sampling을 쓰면 sparse해지겟네요?
넹 • Negative Sampling을 적용하면 SGD가 매우 희소한 그래디언트를 가지게 됨. • 전체 단어 벡터를 업데이트하는 것이 아니라, 일부 단어만 업데이트하므로 연산량이 절감됨. • SGD와 Negative Sampling의 조합 덕분에 Word2Vec은 대규모 데이터에서도 효율적으로 학습될 수 있음.
왜 같이 등장할 확률을 바로 안구해요?
- co-occurrence matrix는 어캐 구할까용?
- window vs document에 따라 달라요
한번 해보죠
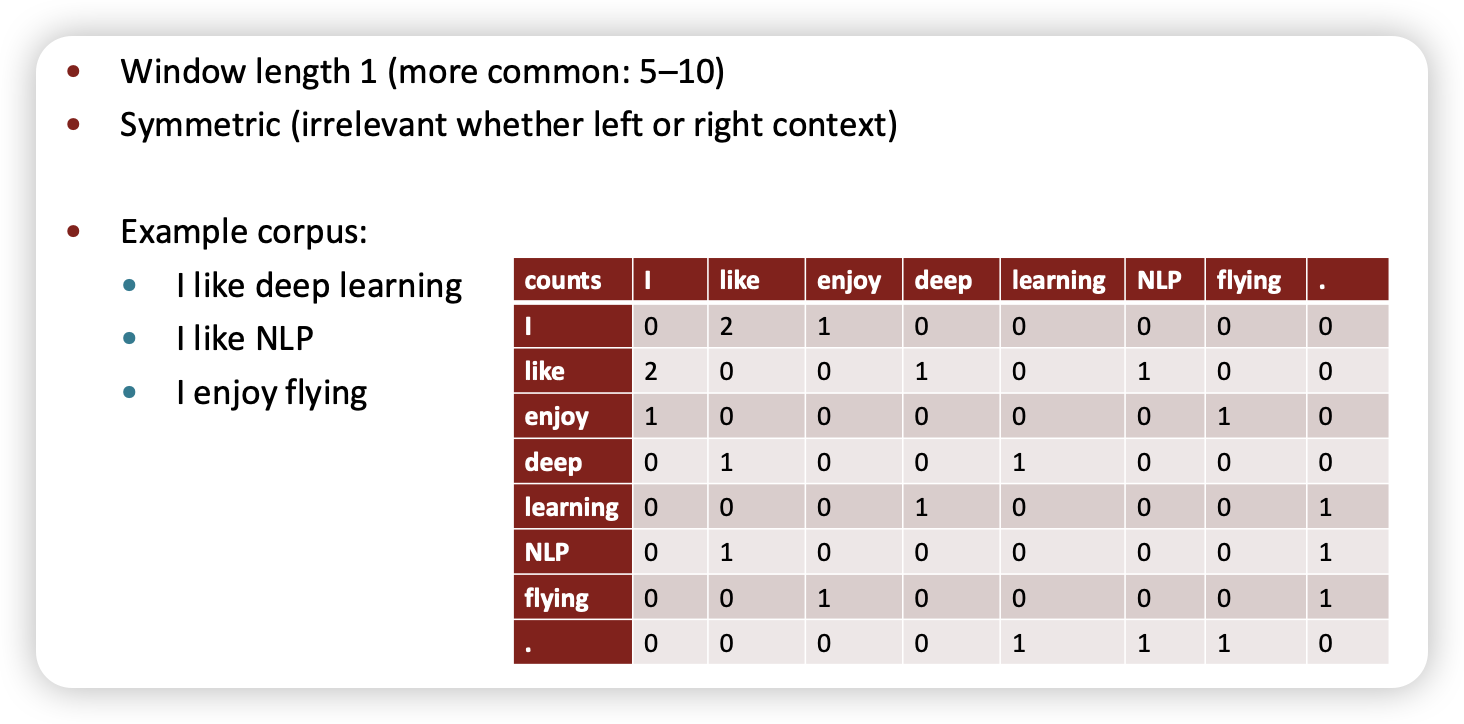 이게 말이 되나요?
이게 말이 되나요?
- 큰 matrix를 차원을 줄여야 해요
- voca 사이즈에 따라 사이즈가 커져요
방법 1. Singular Value Decomposition
사실 잘 안돼요
- counts를 scaling 해야함
- Use correlations instead of counts, then set negative values to 0
- Ramped windows that count closer words more than further away words
encoding meaning을 더 잘하게 할 수 없을까? → GloVe
어캐했어요?


Intrinsic word vector evaluation
Intrinsic
- 모델 output만 가지고 평가함
- correlation을 얼마나 잘 평가하는가
Meaning similarity
- 사람한테 직접 점수를 매겨서 label로 사용
- 모델링을 잘했으면 비슷한 값을 가질 듯
Extrinsic
- 어플리케이션의 목적(다른 task)에 따라 지표 평가
- named entity recognition (개체 인식 태스크)
- 어디서부터 단어가 entity이고, classifiy를 얼마나 잘하나
word sense
단어가 여러가지 의미(모호함)를 가질 때, 어떻게 벡터로 표현할까요?
- 비슷한 의미를 가진 cluster word windows 다른 의미를 가질 때(다른 클러스터에 있을 때), 각각을 다르게 배치할 거에요

NER(Named Entity Recognition)
문장 안에서 단어(token)가 사람, 장소, 날짜… 등 entity로 감지하고 분류하는 작업

어따 써용?
- 문서 내 특정 entity 감지
- entity 감정 분석
그럼 classification를 잘해야함
multiclassify or binary classify
구현 어캐 해용? 간단한 binary classify

classification
supervised learning → 학습할 데이터셋이 다 있음

Neural classification Typical ML softmax classifier 은 라벨(y)에 대해 softmax을 최대로 하려고함
- 즉 linear boundary를 구할 수 밖에 없다 ㅜㅜ
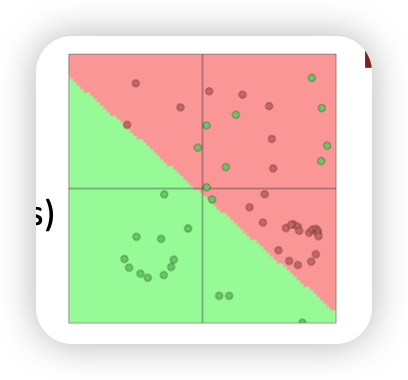
만약에 여러 층을 끼게 된다면 neural network classifier
→ non-linear한 것도 구할 수 있다!
→ non-linear decision boundary
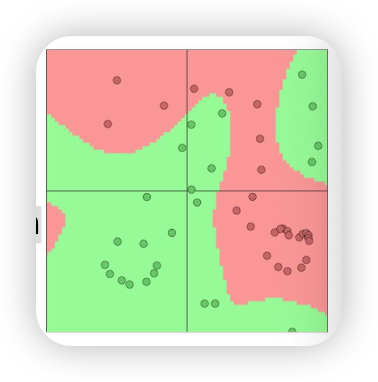
The word vectors x re-represent one-hot vectors, moving them around in an intermediate layer vector space, for easy classification with a (linear) softmax classifier

- x: (1-hot vector)
- hidden layer : non-linear function (logistic(sigmoid), ReLU)
- u 내적
- function predict
non-linear function
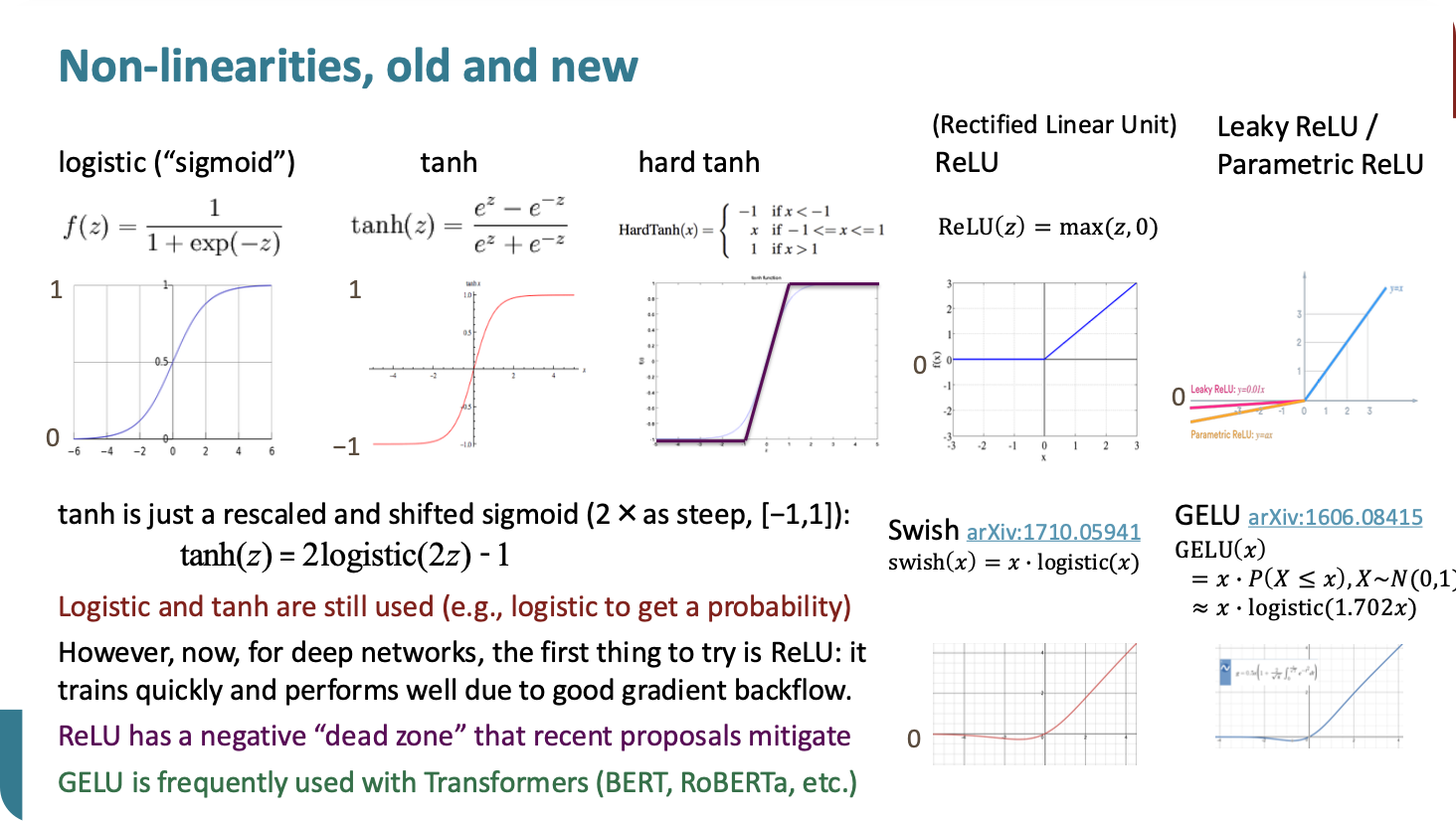
- logistic, tanh는 지금도 쓴다. 나머진 문제가 좀 있음
- ReLu → 0이하 에러 전파 x
- GELU → 오 낫밷
- 왜 non-linear가 필요한가용?
- linear한애는 결국 얼마나 쌓아봐야 결국엔 한층 쌓은거랑 똑같다
Cross Entropy Loss
얼마나 두 distribution이 비슷한가를 측정하는 지표
→ correct class, predict class 의 CEL 를 높히는 방향으로 학습을 함
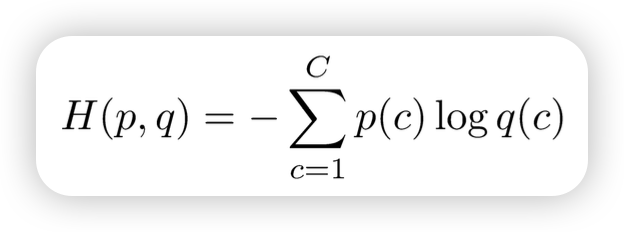
- p : input으로 넣는 1-hot vector → [0, …, 0, 1, 0, …, 0]
Gradient Descent
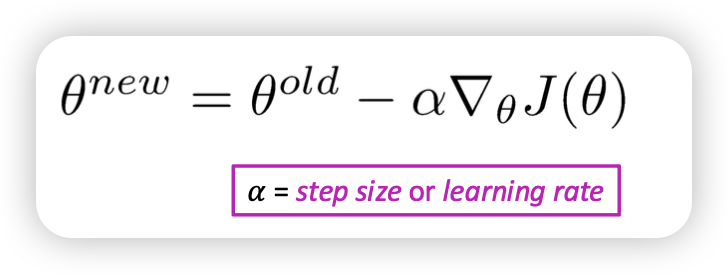
Addition
un-supervised → 특성 추출