lecture key point
- 왜 RNN이 등장했을까?
- RNN의 문제점이 뭐였을까?
Language Model
언어모델은 현재 문맥에서 다음 단어가 뭐가 나올지 예측하는 모델
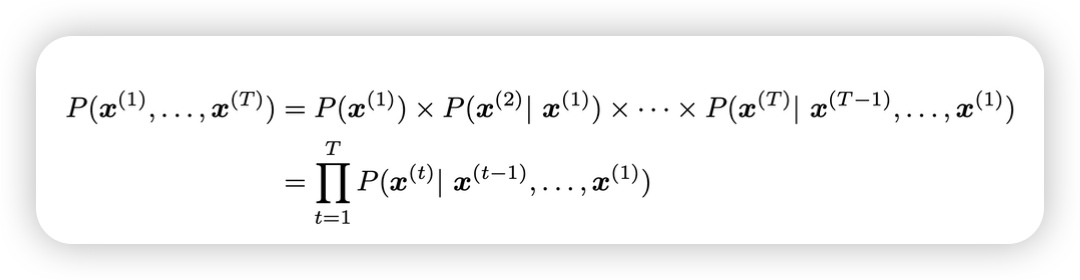
usage
- Predictive typing
- Speech recognition
- Handwriting recognition
- Spelling/grammar correction
- Authorship identification
- Machine translation
- Summarization
- Dialogue
next-word prediction으로 무슨 태스크를 수행할 수 있을까?
- trivia
- syntax
- coreferene
- lexical semantics/topic
- sentiment
- reasoning (hard…)
- basic arithmetic
GPT2
Stylistically correct, content wise, questionable
GPT3
in-context learning이 가능해졌다! backround로 정보를 미리 가지고 question에 대답이 가능해짐
N-gram Language Model
GPT 전에 아주 고전적인 모델들
확률은 어캐 구하는데요? corpus에서 개수 세요…
뭐가 문제였을까요?
sparsity problem
- 자주 등장하지 않는 단어들(count가 적은)은 확률이 0임 → smoothing으로 개선
- 애초에 context가 없었다면? → backoff (n-1 gram으로 처리)
storage problem corpus를 확장하면 할수록, 문장이 길어질 수록, count를 저장하기 어려워짐
generating text은 어떨까?
incoherent. We need to consider more than three words at a time if we want to model language well.
But increasing n worsens sparsity problem, and increases model size…
evaluation metric
- perplexity : 낮으면, corpus에서 해당 context가 나올 확률이 높다! → 모델링 잘했네~
neural language model은 어땟는감
- window-based neural model
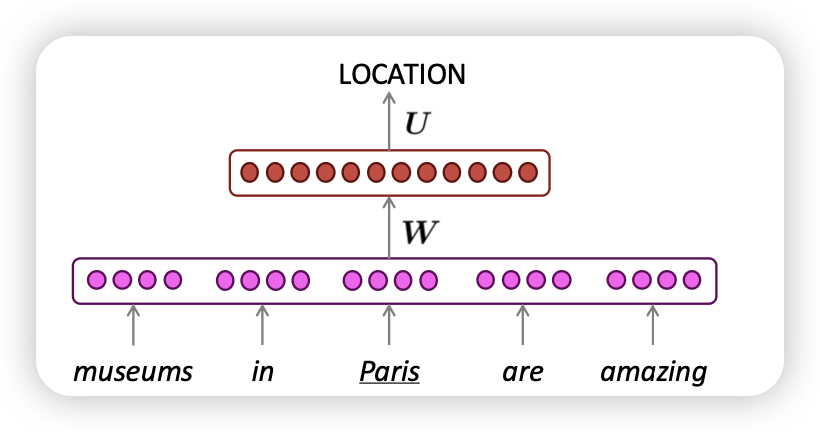
A fixed-window neural Language Model
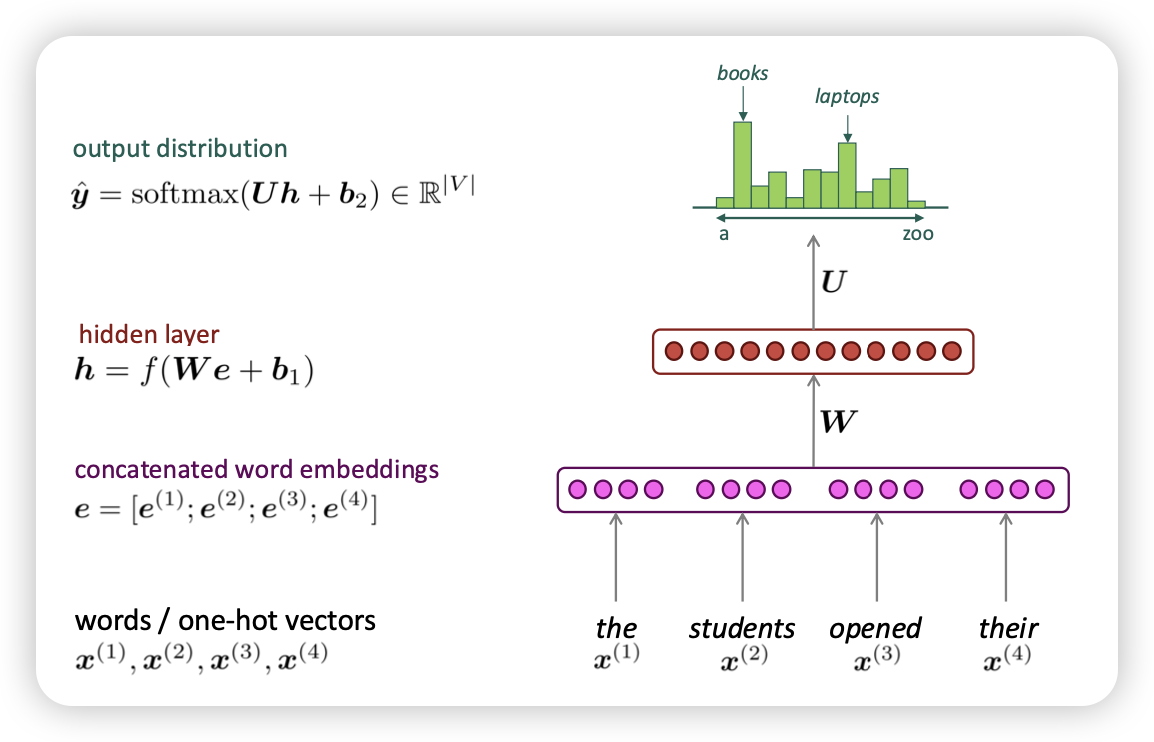
- 가운데 단어가 아닌, 앞선 단어로 window input으로 넣는다!
- NER이랑 뭐가 다름? → output이 실수였던 거랑 다르게 얘는 vector
sparsity problem이 해결되엇음→ 왜 why???- storage 문제 해결
- fixed window 가 커지기 어려움 (flexible한 input은 안됌)
- input의 순서가 보장되지 않는다.
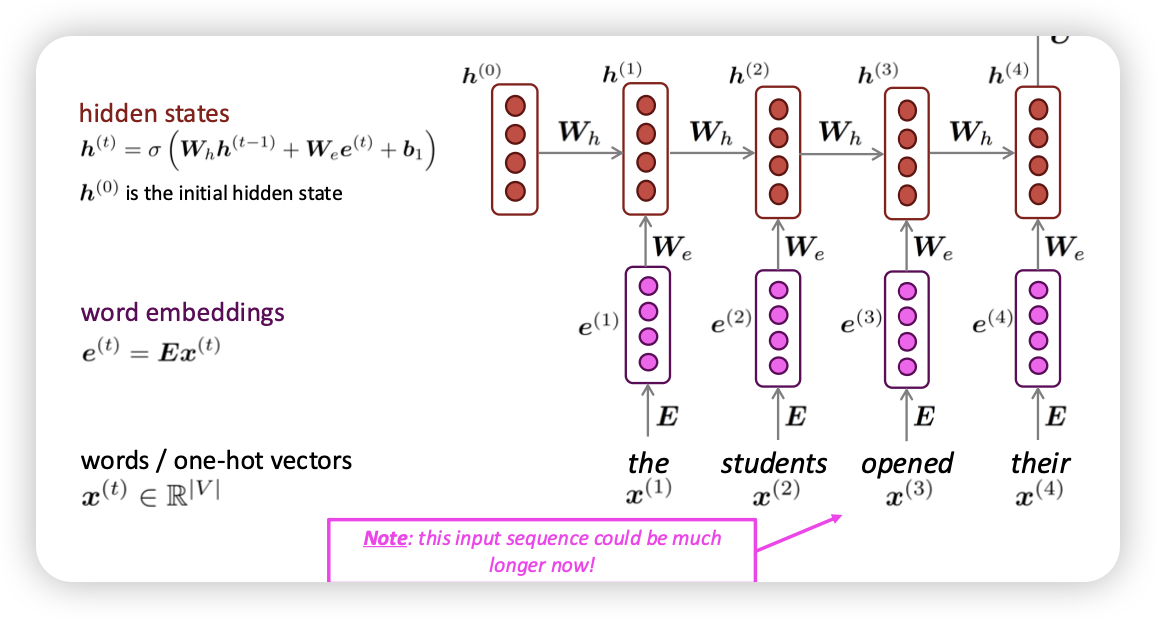
RNN
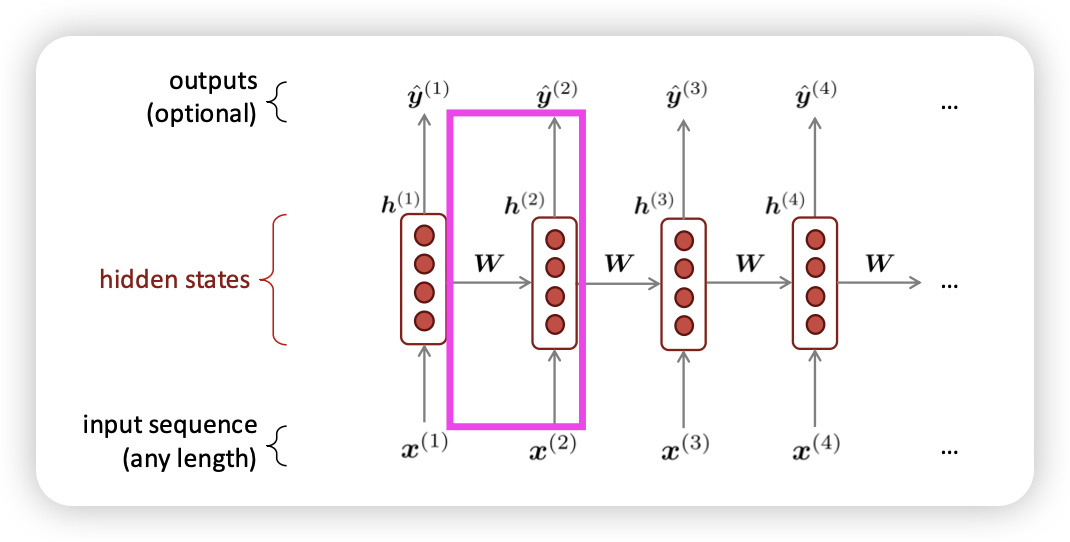
- 현재 시점에 들어온 input을 처리하는데, 이전 context도 반영한다!
- I have fruit →
fruit처리시에I have도 같이 반영됌
- I have fruit →
-
word embedding을 위한 E metric
-
hidden layer는 옛날엔 sigmoid나 hyper tanh썻음
-
마지막 layer에서 값을 통해서 vector 출력
- 이전 layer를 flexible하게 늘릴수 있음 → window size 변경 가능
- 모델 사이즈가 크게 늘어나지 않는다 (결국 , 만 하니까)
-
순서에 대한 정보도 활용
-
Recurrent 연산은 느리다.. (한번에 한 step씩 순서대로 처리)
-
너무 이전의 step에 있는 정보는 전파가 잘 안된다
Train RNN
Teacher Forcing (정답지 가지고 옆에서 계속 훈수두기)
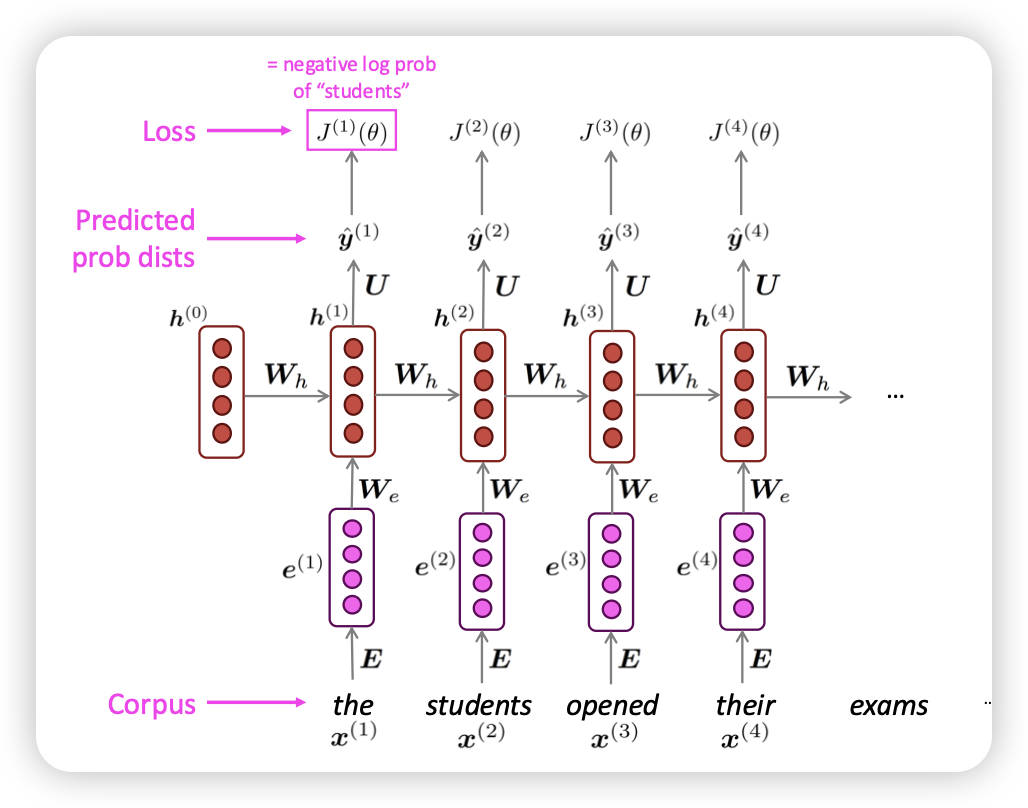
forward
- load big corpus
- compute output distribution
- loss function(cross entropy) negative log probablity
- loss의 평균을 구함
실제론
- 전체 corpus를 하기엔 너무 힘듬
- sentece, document 단위로 자른다!
backward
output을 내는데 어느놈들이 영향을 미쳤는가?
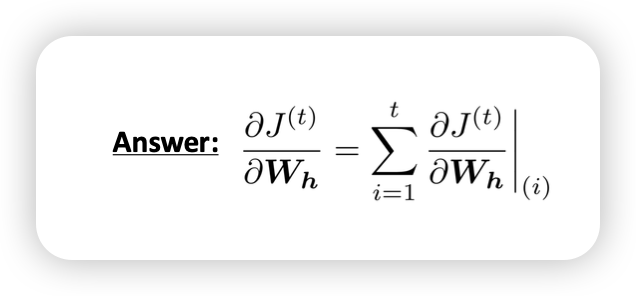
Multivariable Chain Rule
두개의 변수로 이루어진 함수의 gradient는 각자의 변수로 미분한 값의 합임
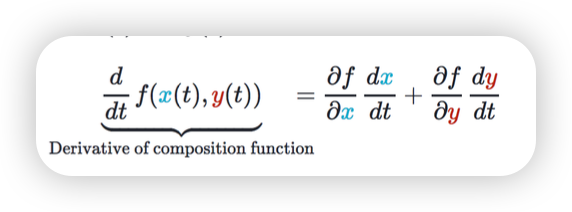
backpropagation through time
 RNN으로 Generating 해볼까?
RNN으로 Generating 해볼까?
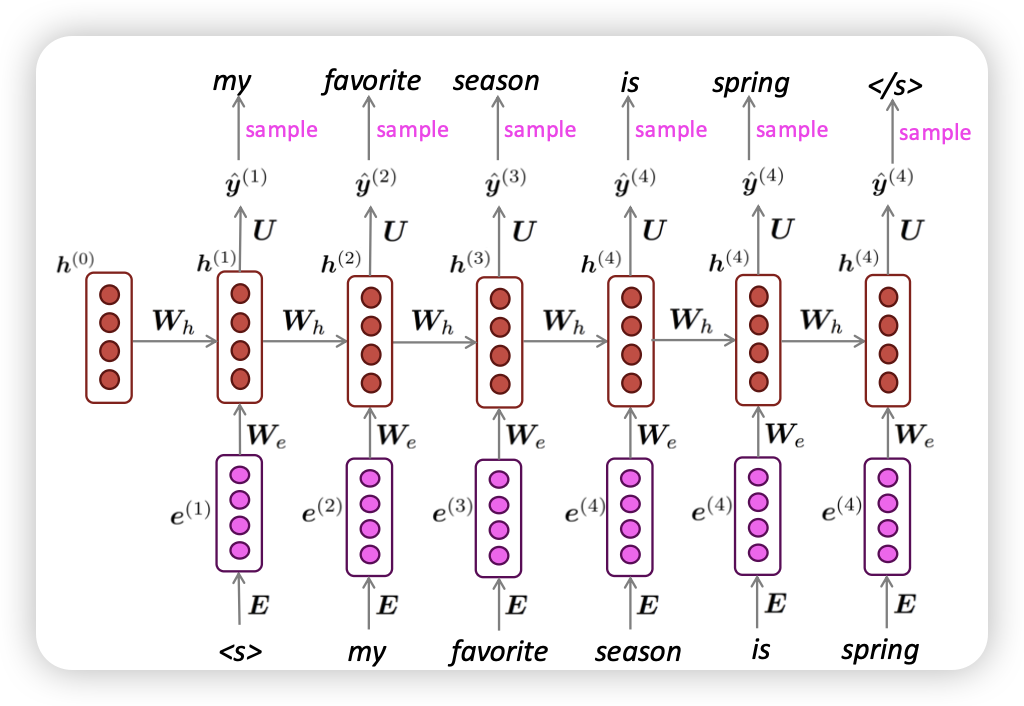
- ngram보다 낫배드한데용?
vanishing gradient
- 중간 step에 있는 gradient값이 너무 작은 경우
- 누적해서 곱하기 때문에 최종적으로 propagation될 gradient가 거의 희미해짐
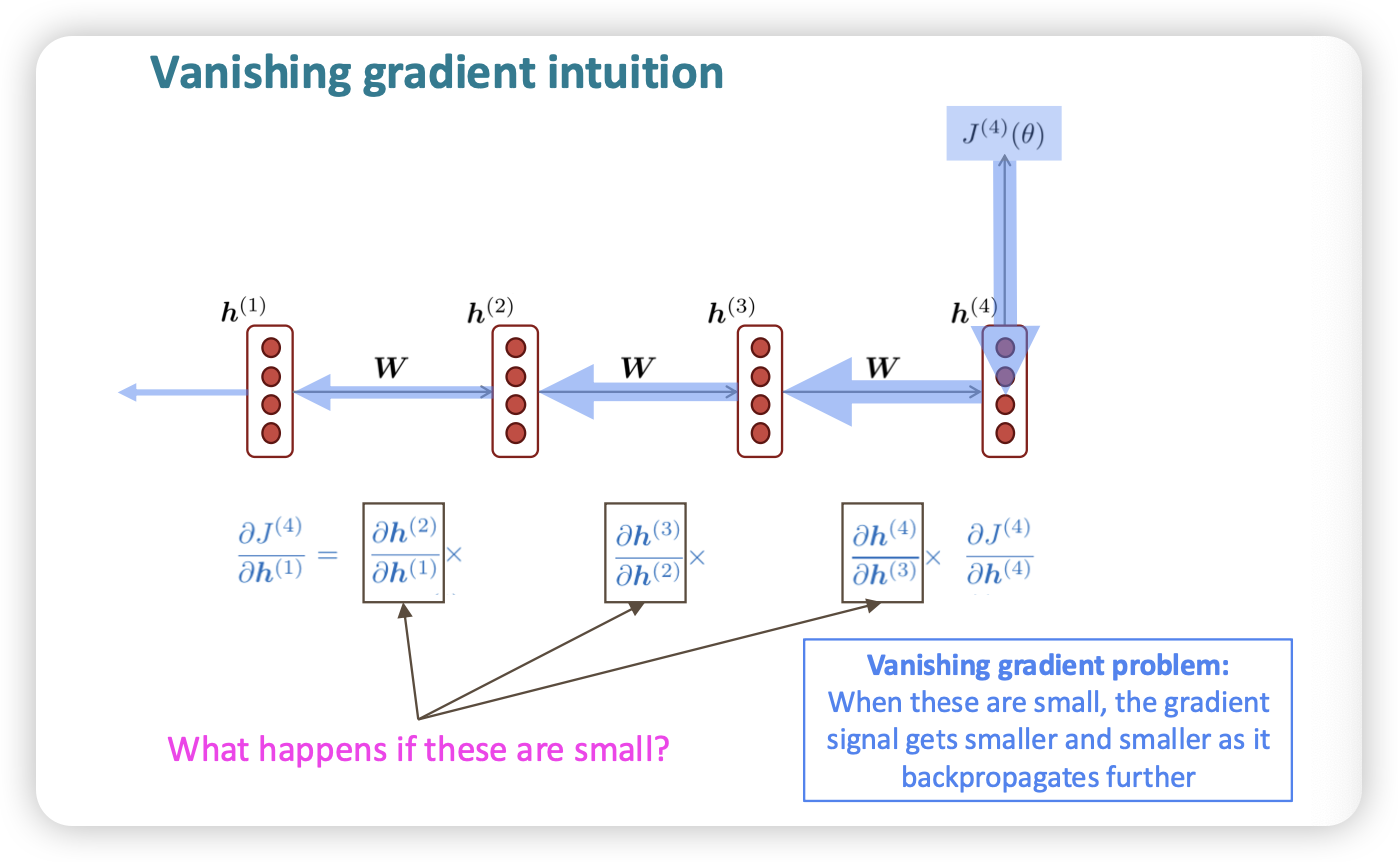
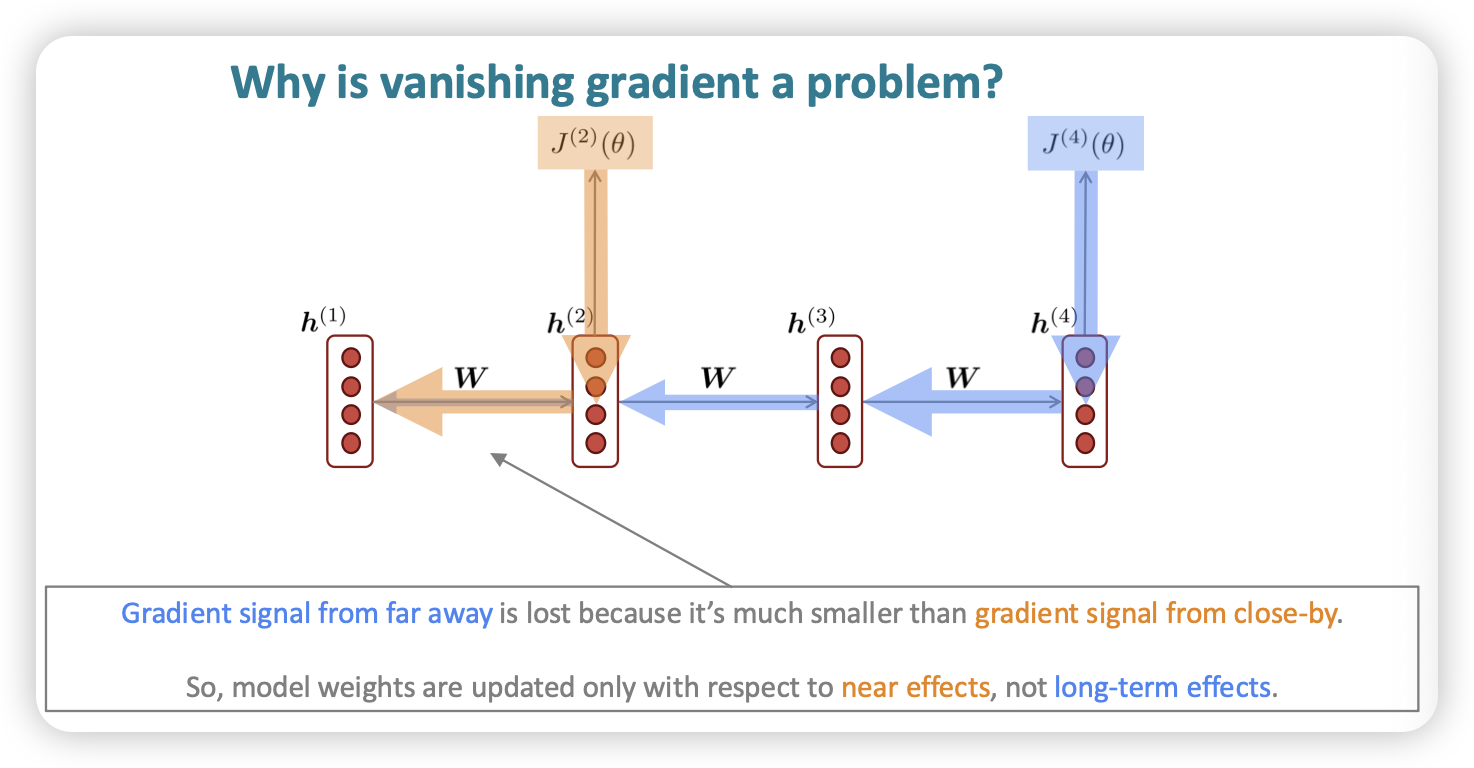 결국, long-term인 경우에 이전 맥락을 잘 반영하지 못하는 경우가 많아졌음
결국, long-term인 경우에 이전 맥락을 잘 반영하지 못하는 경우가 많아졌음
수식 증명

- 결국 의 경우 거리가 멀수록 0에 수렴하는 걸 확인할 수잇음
- 게다가 우리는 non-linear function을 쓰기때문에 0에 더욱더 가까워짐
Solution
- 새로운 모델 아키텍처 : 기존 이전 input만 받는 vanilla RNN에서 별도의 메모리를 만들자
- LSTM
exploding gradient
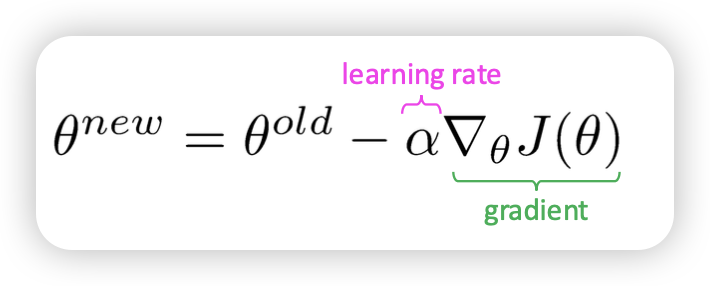
- gradient가 너무 크게 되면, 너무 이상한 포인트로 넘어가서 못돌아올 수도
- RNN만의 문제가 아니긴 함
Inf,NaN이 떠서 실패한 경우도 있다
Solutuon
- Gradient Clipping
- threshold보다 벡터 크기 넘으면 방향은 두고 크기만 줄임
-
Intuition