Language Model
Define
- 다음 단어가 나올 확률 모델(probalilstic model)
- 기존 단어들을 조합해서 다음 단어가 나올 확률을 계산함
Chain Rule
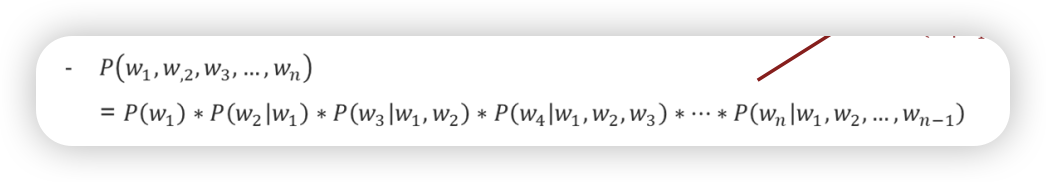
그럼 N-gram이 뭔가
앞의 모든 단어를 모두 확인할 수 없으니 approximation을 통해 앞선 n개의 단어만 놓고 확인함
2개 보면 bigram n개 보면 ngram
Markov assumption
앞선 모든 context를 보기엔 어려움 앞선 단어 몇개만 보고 다음 나올 단어 추정
단어 짱짱 많은데 어떻게 확률을 추정할 수 있을까
Generation with n-gram language model
- 다음 나올 단어를 생성하는 방법은요?
- 미리 확률 테이블을 만들어놓기
- n grams을 넣고 가장 확률 높은 단어 넣기
- 2 반복
- generation 방법
- top-k vs top-p sampling
- top-k : 상위 k개만 선택
- top-p : 상위 top의 합이 일정 임계치가 되는 애들 선택
 long tail? → top-k중 일부만 크고 나머진 구림
long tail? → top-k중 일부만 크고 나머진 구림
- top-k vs top-p sampling
Evaluation
Extrinsic evaluation
- real-world task or downstream application
- 모델 자체보다 실제 어플리케이션이 얼마나 부합하는가 판단 지표
- Hard to optimize downstream objective (indirect feedback)
Perplexity (ppl) - Intrinsic evaluation
얼마나 다음 단어를 잘 예측하는가 지표
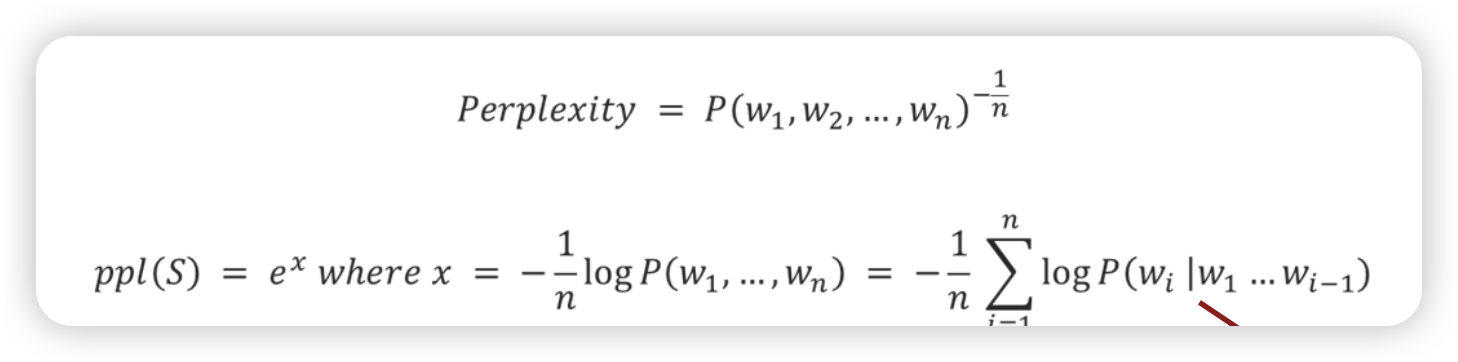
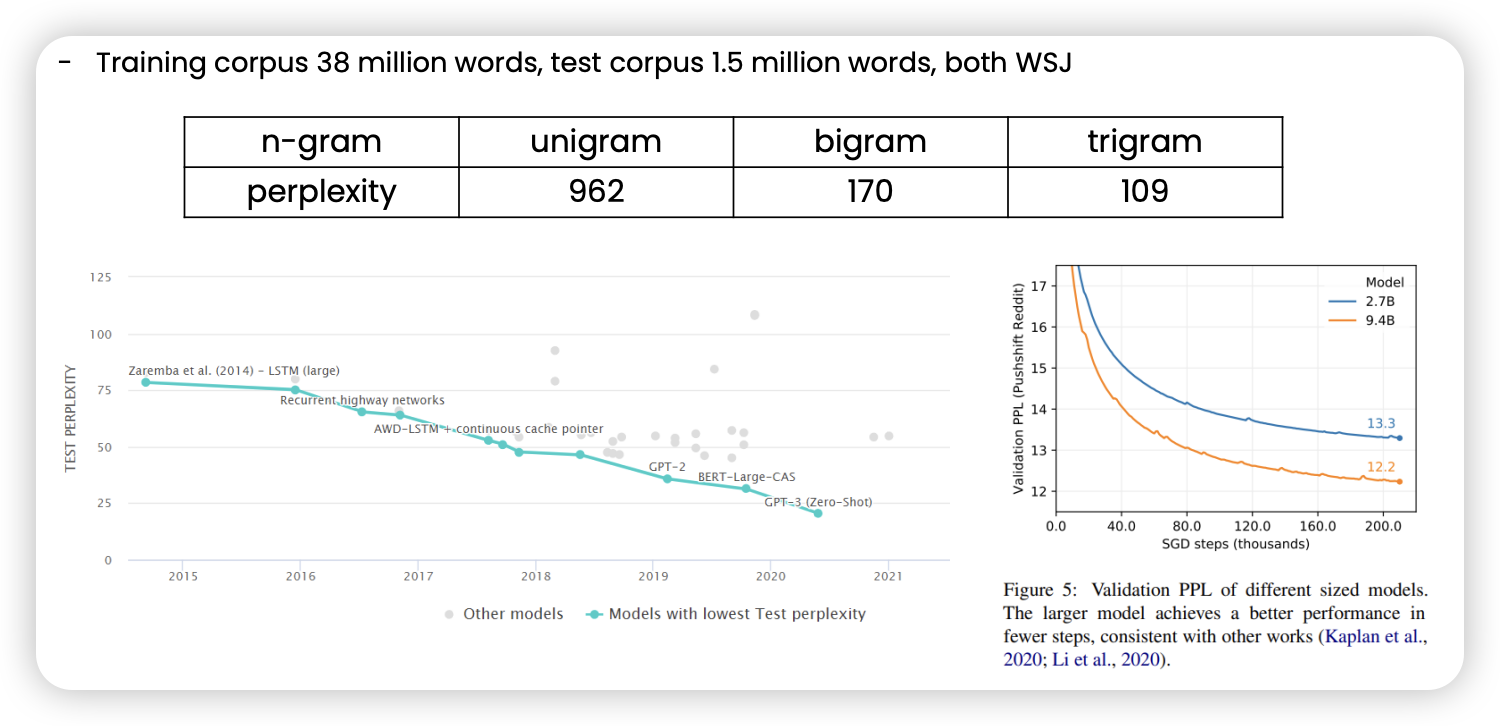
- 모델이 발전할 수록 perplexity가 낮아진다
Smoothing
왜 필요한데용?
- 모든 n-grams 조합이 학습데이터에 없을 수 있음(조합이 너무 많기 때문)
- trainning set에 없으면 확률이 0로 계산되어버리기 때문
- P(affray | voice doth us) = 0 → P(test corpus) = 0
- Perplexity is not defined
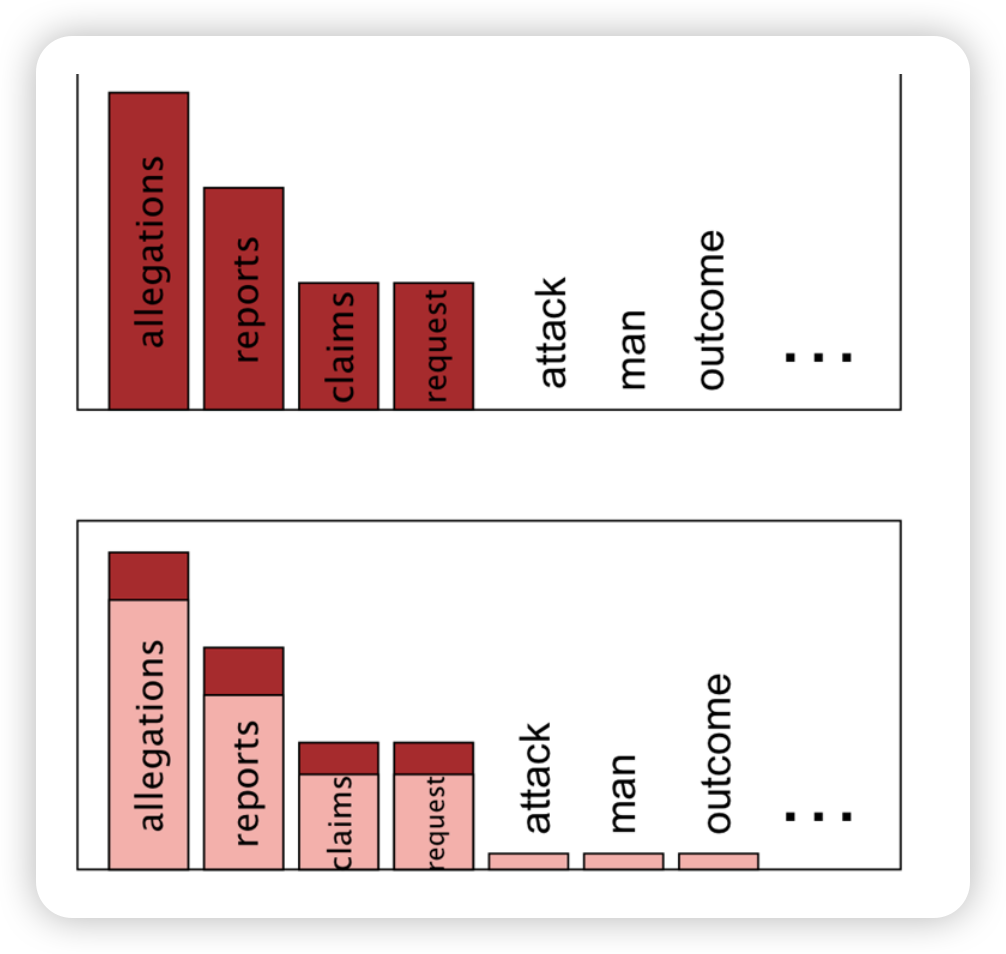
Sparsity in language
- 실제로 단어들 빈도 확인해보면 이럼
- Long tail of infrequent words
- Most finite-size corpora will have this problem.
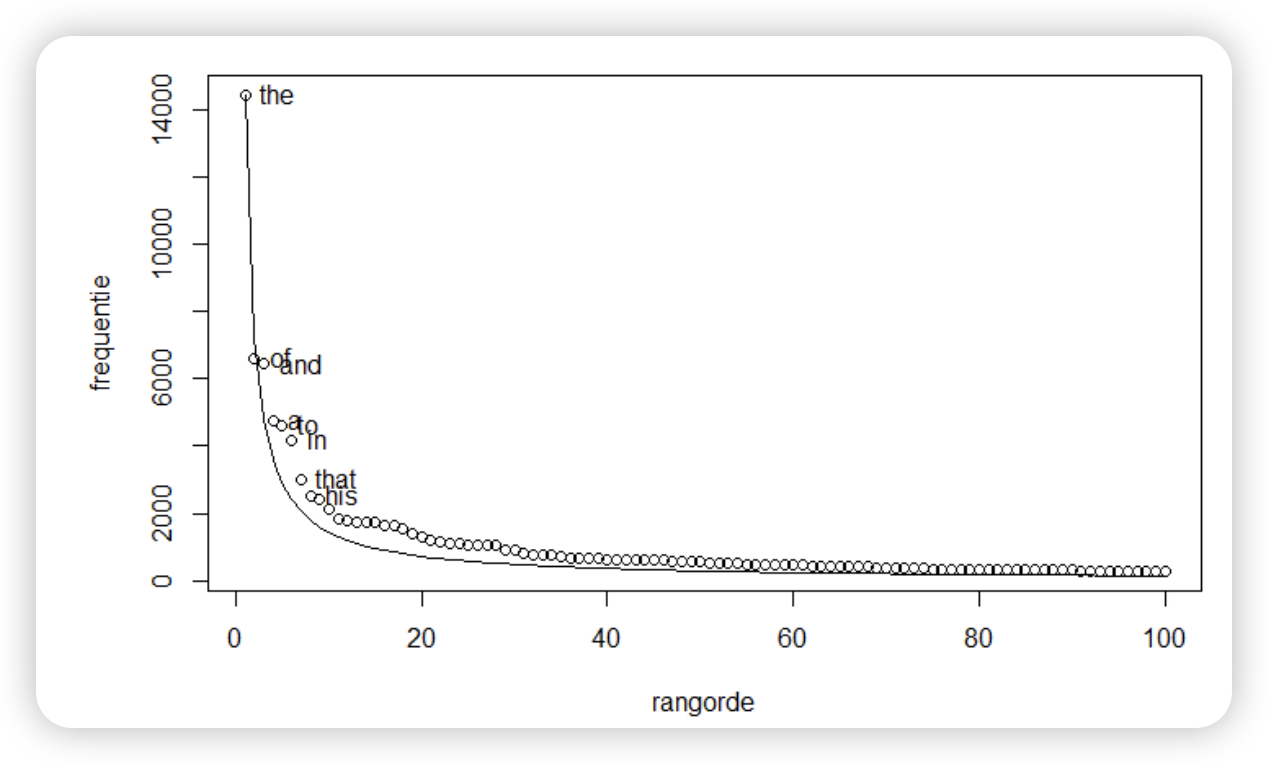
어캐함
Laplace smoothing
- 확률에 일정한 알파만큼 더해준다~
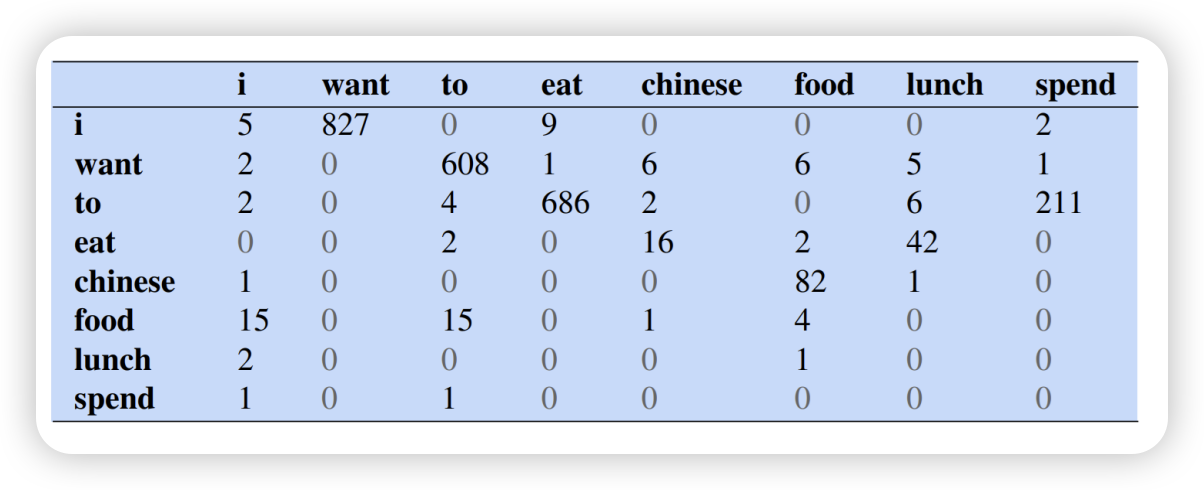
- 기존 frequency
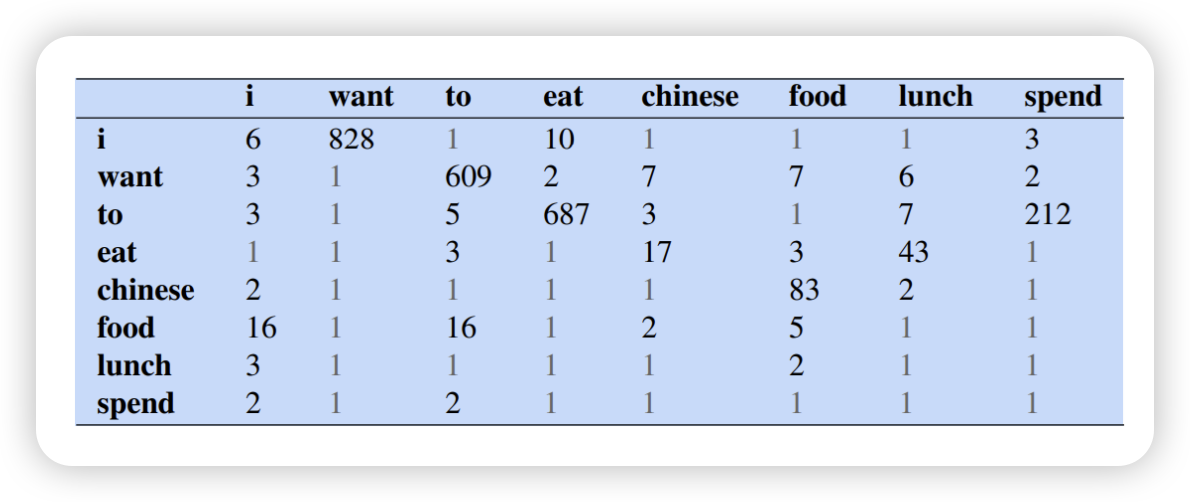
- 알파 더하기
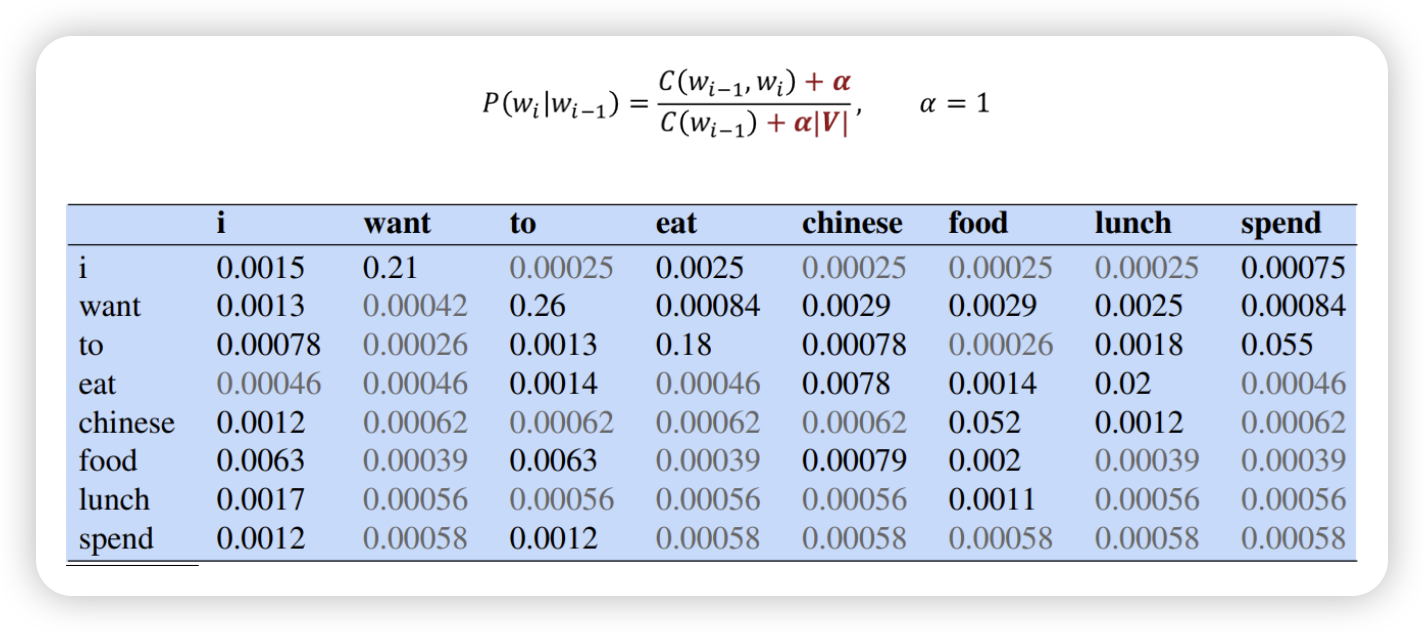
- 다시 나눠주기~
Linear interpolation
- 특정 n gram의 확률이 없기에 n-1, n-2 gram으로부터 가져온다
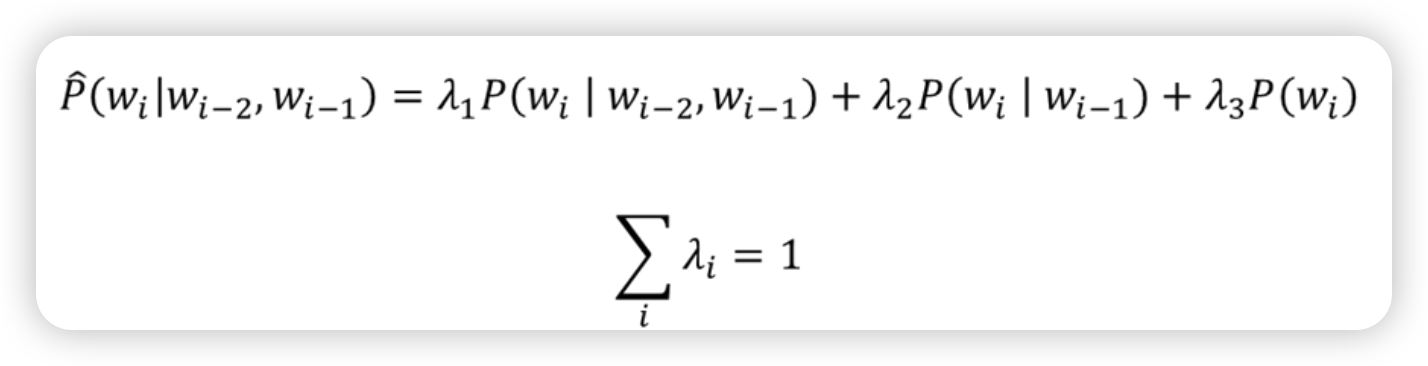
- 이 때 앞의 가중치(상수)는 linear하게 만든다
이 상수(하이퍼 파라미터)는 어캐 찾음?
- tranning set에서 n gram 확률 구함
- validation set에서 확인
- test set에서 확인
Discounting
- corpus에서 일정 값만큼 count 빼기
- count가 0인애들은 n-1 비율만큼 배분해주기!
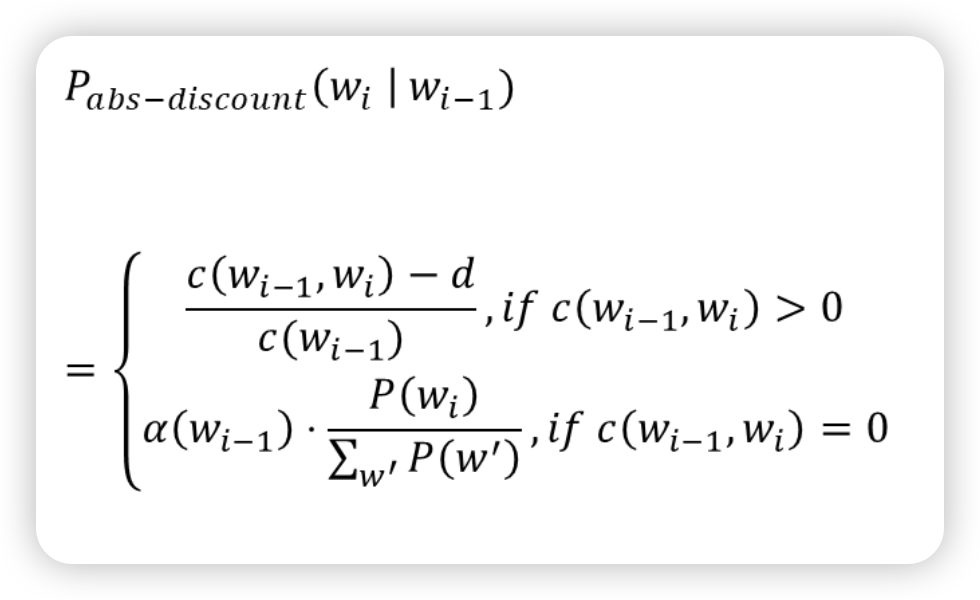
Addition
NN 관점에서 생각해보면,
비슷한 단어들의 집합들은 count가 없어도 vector space로 표현하기에 이런 고전적인 smoothing 과정은 필요 없을 수도 있다!
이후 RNN, transformer에서는 모델 아키텍처 개선으로 성능 발전
Dataset
train, valid, test 배분
특정 모델 학습 목적
- 트레이닝 데이터의 특징을 잘 잡아야함
- 너무 overfitting 안되어야함
- 학습에 사용하지 않은 validation set을 통해 학습이 잘 이루어져 있나 확인
국룰 8:1:1
- corpus에서 배분
- 보지 않은 테스트셋을 얼마나 잘 생성하나?
- 이 trainset에 얼마나 fit한지, not overfit,