A binary logistic regression unit

- 사람 뉴런과 비슷하게 생겼다~
- bias?
- weight?
Neural Nets
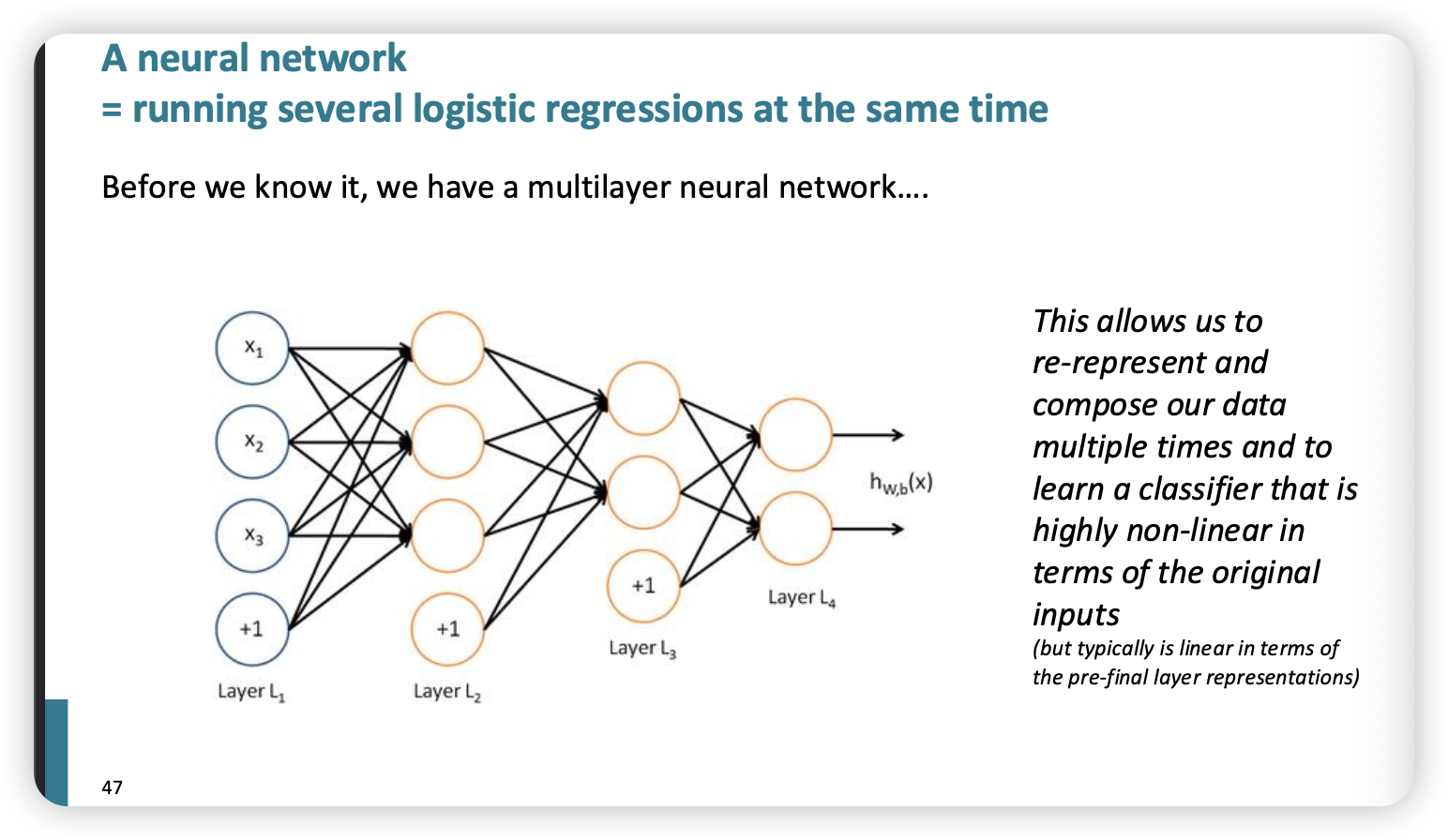
- weight, bias 모두 matrix로 표현한다~
Gradient
- activation fuction의 W,b를 조절하기 위해 얼마만큼 이동할지 gradient로 결정

결과


- h : hidden vector
- s :


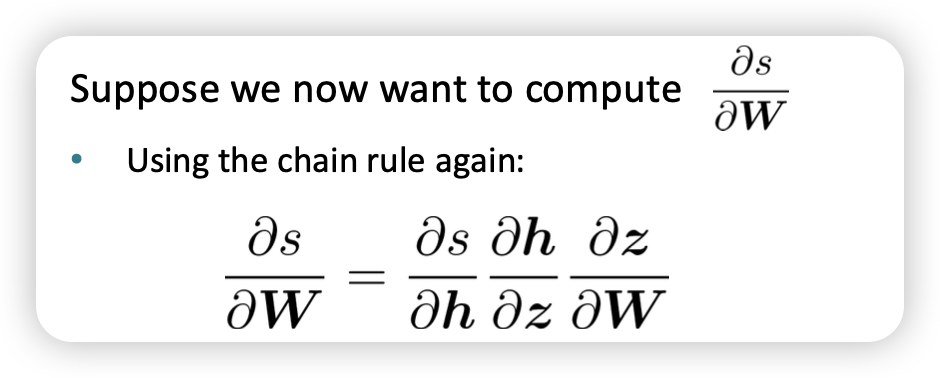
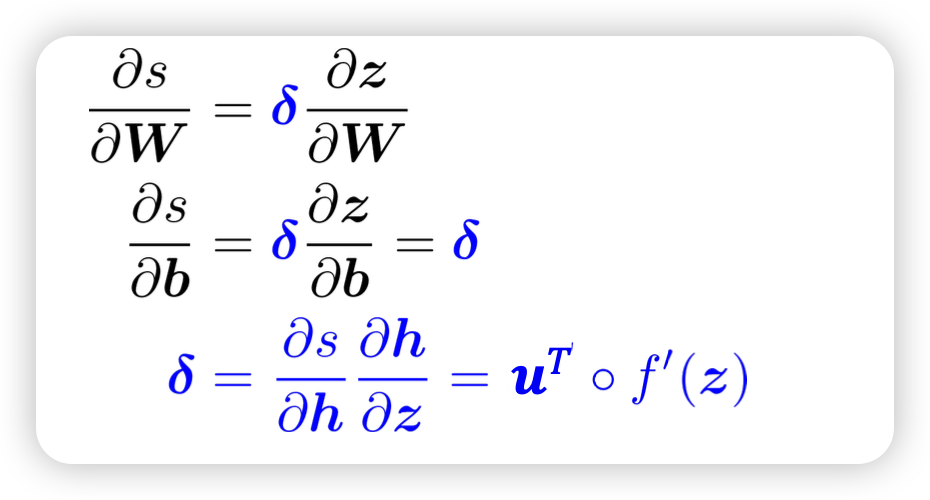

Backpropagation
Forward Propagation
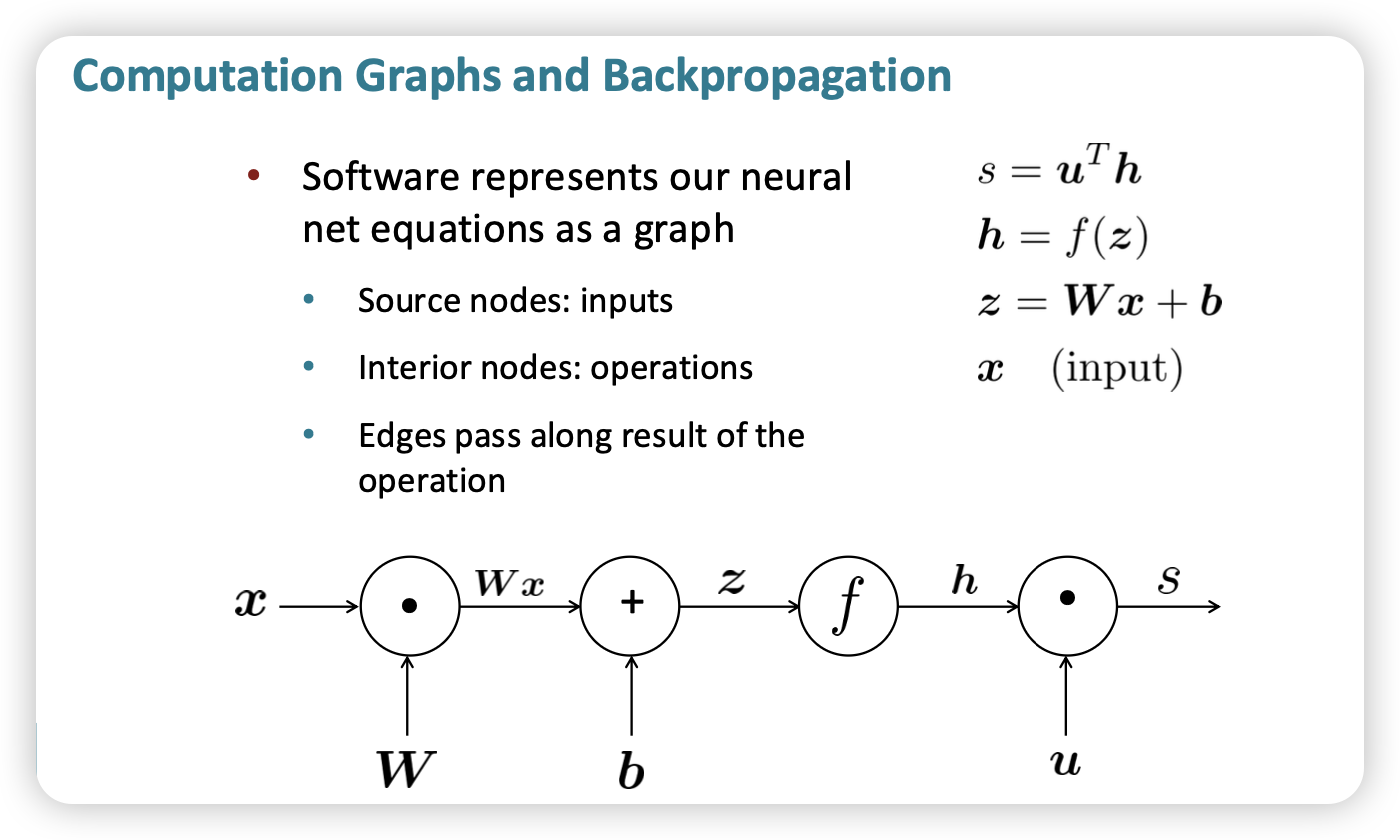
- 앞선 노드에서 계산한 output을 다음 노드에게 전달함
Backpropagation
Overview
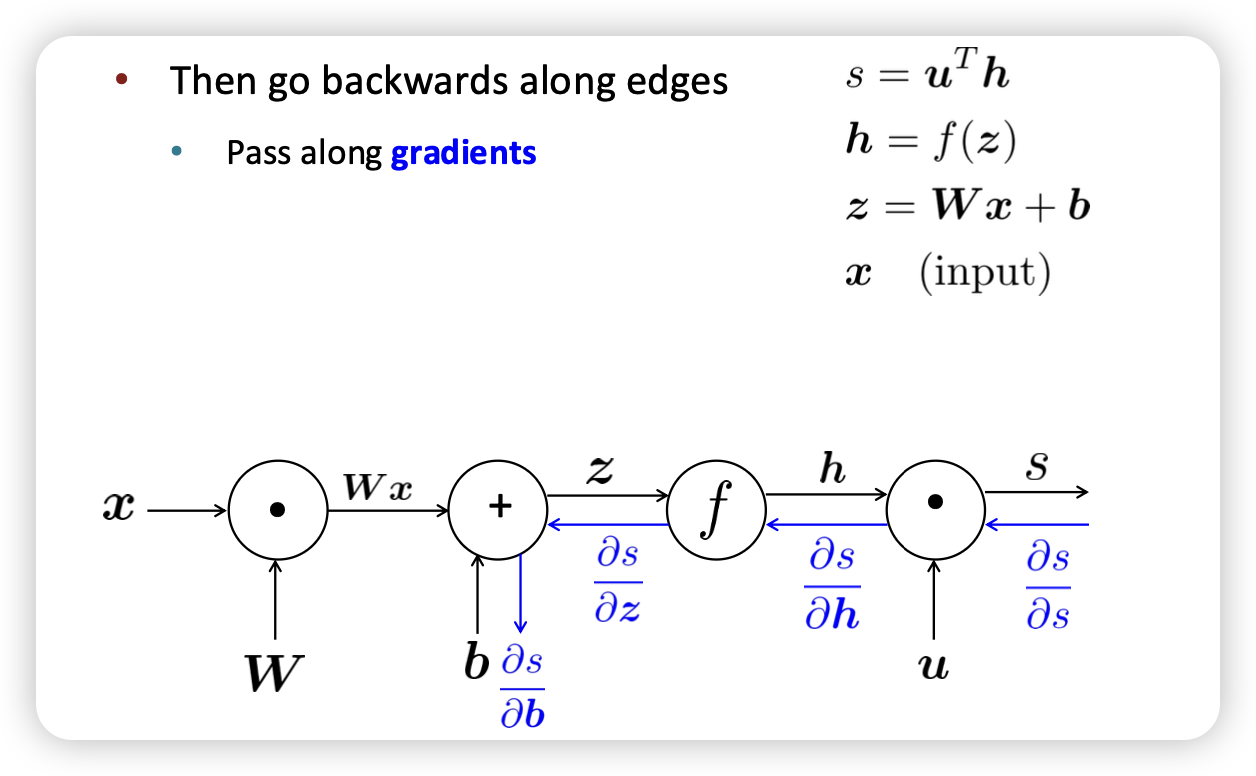
Single node
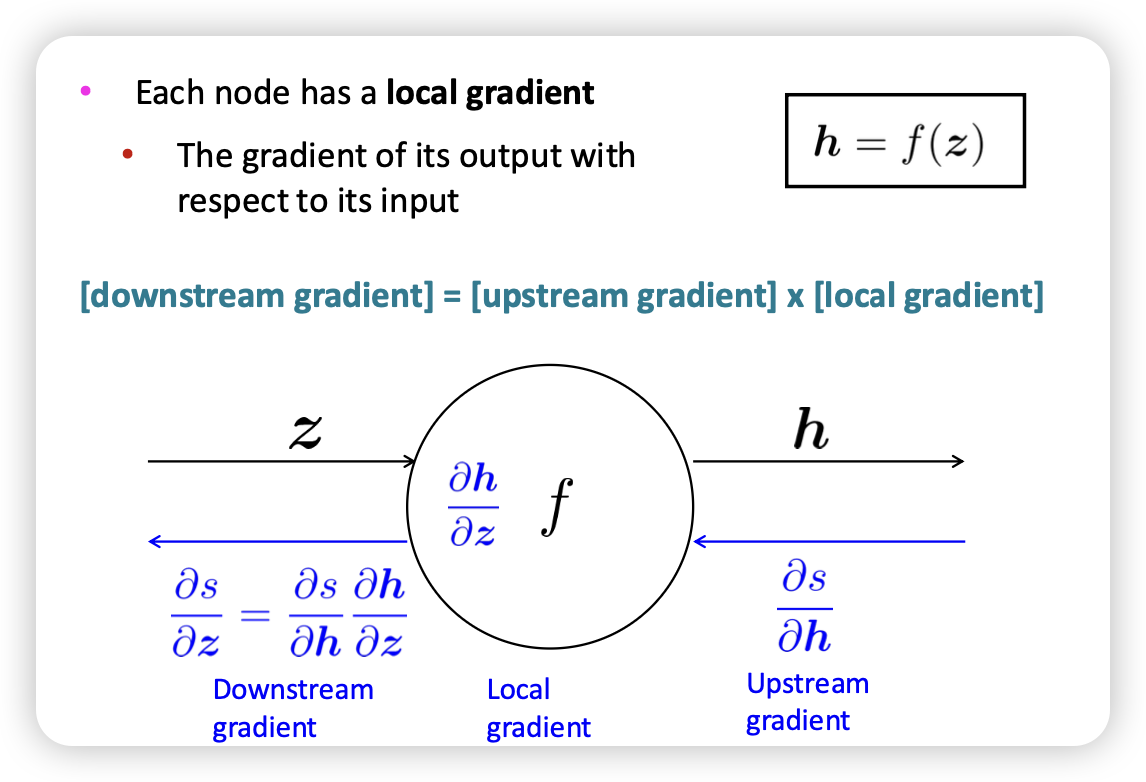
- Bprop → input의 gradient을 전달
upstream * local = downstream
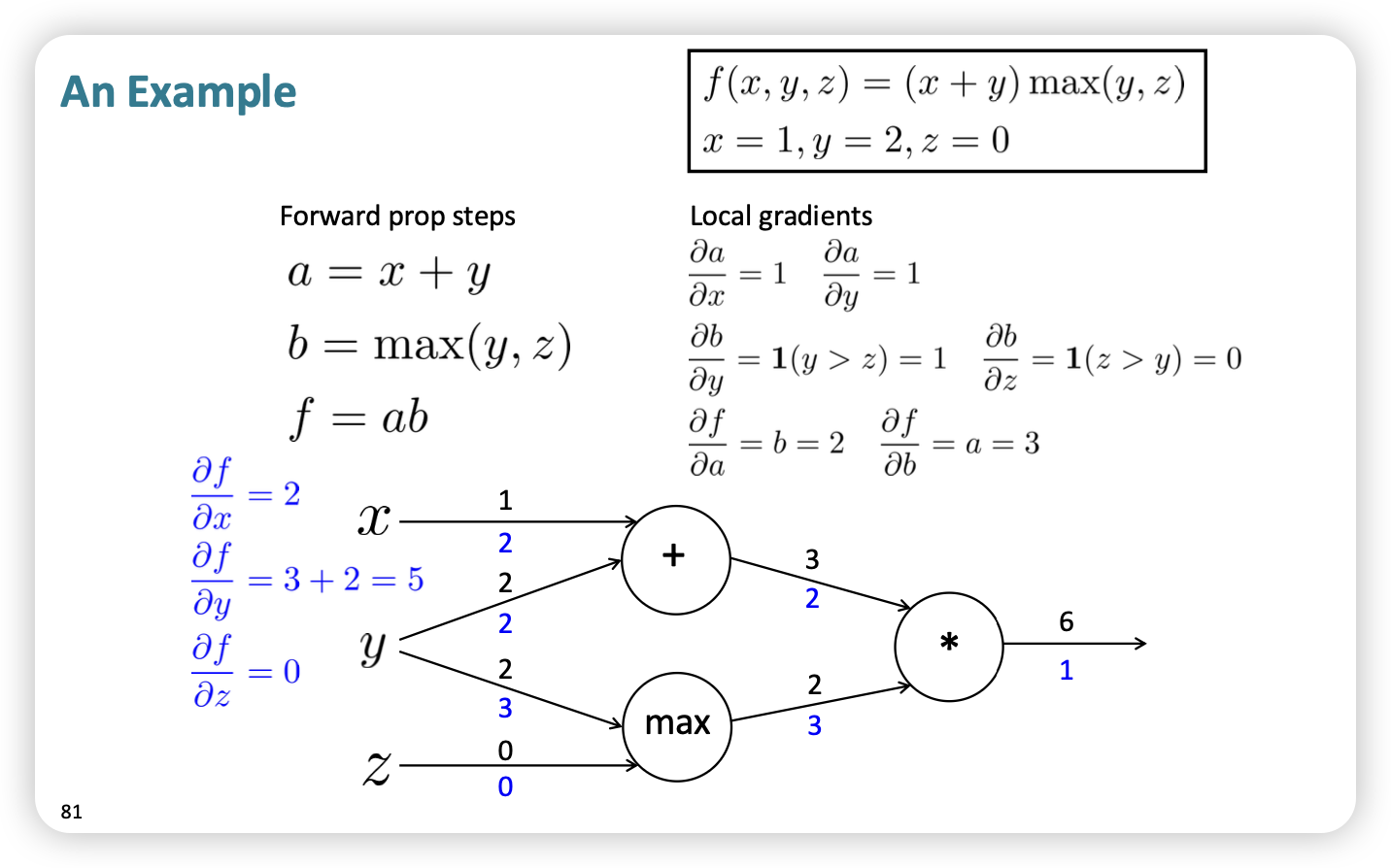
- max의 경우 indicator function 이므로 range에 따라 local gradient 찾기
- y의 경우 다수의 input을 진행하므로 gradient sum 진행
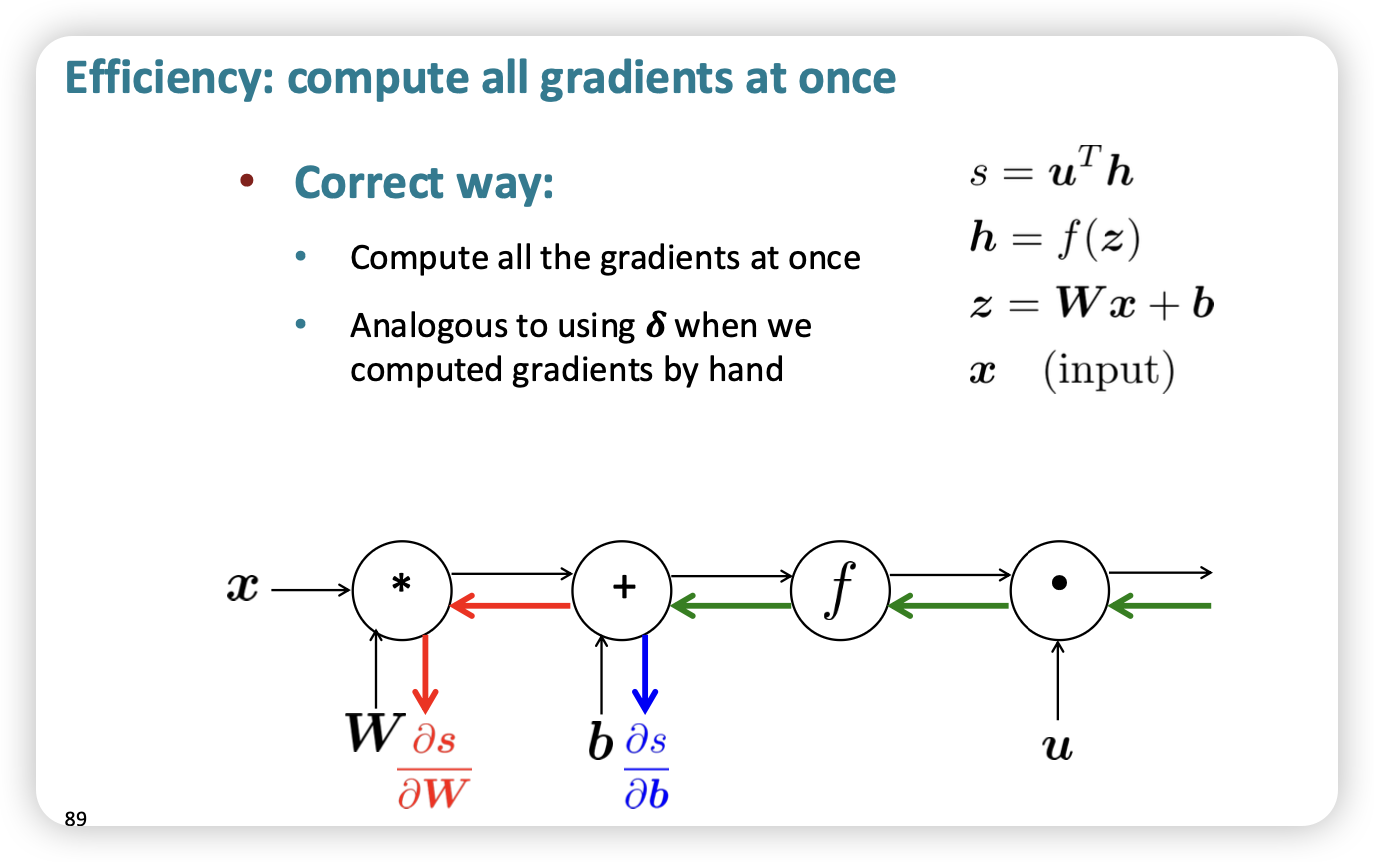
- 공통으로 pass되는 gradient(downstream)를 저장해두었다가 쓰자
실제?
- Done correctly, big O() complexity of fprop andbprop is the same
- In general, our nets have regular layer-structure and so we can use matrices and Jacobians…
- forward , backward 연산량은 비슷함

- gradient를 직접 구하기 힘들면 체크용도로 이렇게 근사를 써도?
- 지금은 쓸일이 없다~