2.6.23 커널 이전에 사용되던 O(1) scheduler(priority 기반 queue)들에서 CFS 스케줄러로 변경
OS에서 배웠던 스케줄링 알고리즘?
preemptive? (2.4 ~ 현재까지) 운영체제가 프로세스의 실행을 실행권한을 뺏는다
- RR (round robbin) : 일정 qunta마다 쪼개서 실행시켰다
non-preemptive? (2.4 버전이하에서 이렇게 썻고) 프로세스가 나 이만큼 썻으니까 yield하면서 스케줄링
- SJF (shortest job first) : 스케줄러가 workload가 얼마나 걸릴지 예측해서 먼저 실행
- FIFO (first in first out) (queue) : 먼저 들어온애 queue에 넣고 그냥 돌리기
현재상황에서 달라진게 (OS에서 배웠던 이후에…)
- 기존은 싱글코어 기반 (CPU 하나였다)
- 4 core 이상의 멀티코어 (vcpu 실제 코어랑)
- CPU 성능이 좋아졌따 (HZ clock 좋아졌다)
- 프로세스 수가 진짜 늘었다
→ 멀티태스킹 (한번에 여러개를 공평하게 실행시키기)에 더 초점이 맞춰져야겟다
CFS scheduler
Completely Fair Scheduler
“Ideal multi-tasking CPU” is a (non-existent :-)) CPU that has 100% physical power and which can run each task at precise equal speed, in parallel, each at 1/nr_running speed. For example: if there are 2 tasks running, then it runs each at 50% physical power --- i.e., actually in parallel.
이를 구현하기 위해 프로세스가 실행된 vruntime을 기준으로 모든 프로세스가 공평하게 CPU를 점유할 수 있도록 함.
- ready 상태의 가장 적은 vruntime을 가진 프로세스 실행
- 점유한 CPU time에 따라 vruntime 증가
- 이후 다음 vruntime이 가장 작은 프로세스 선택
RBtree
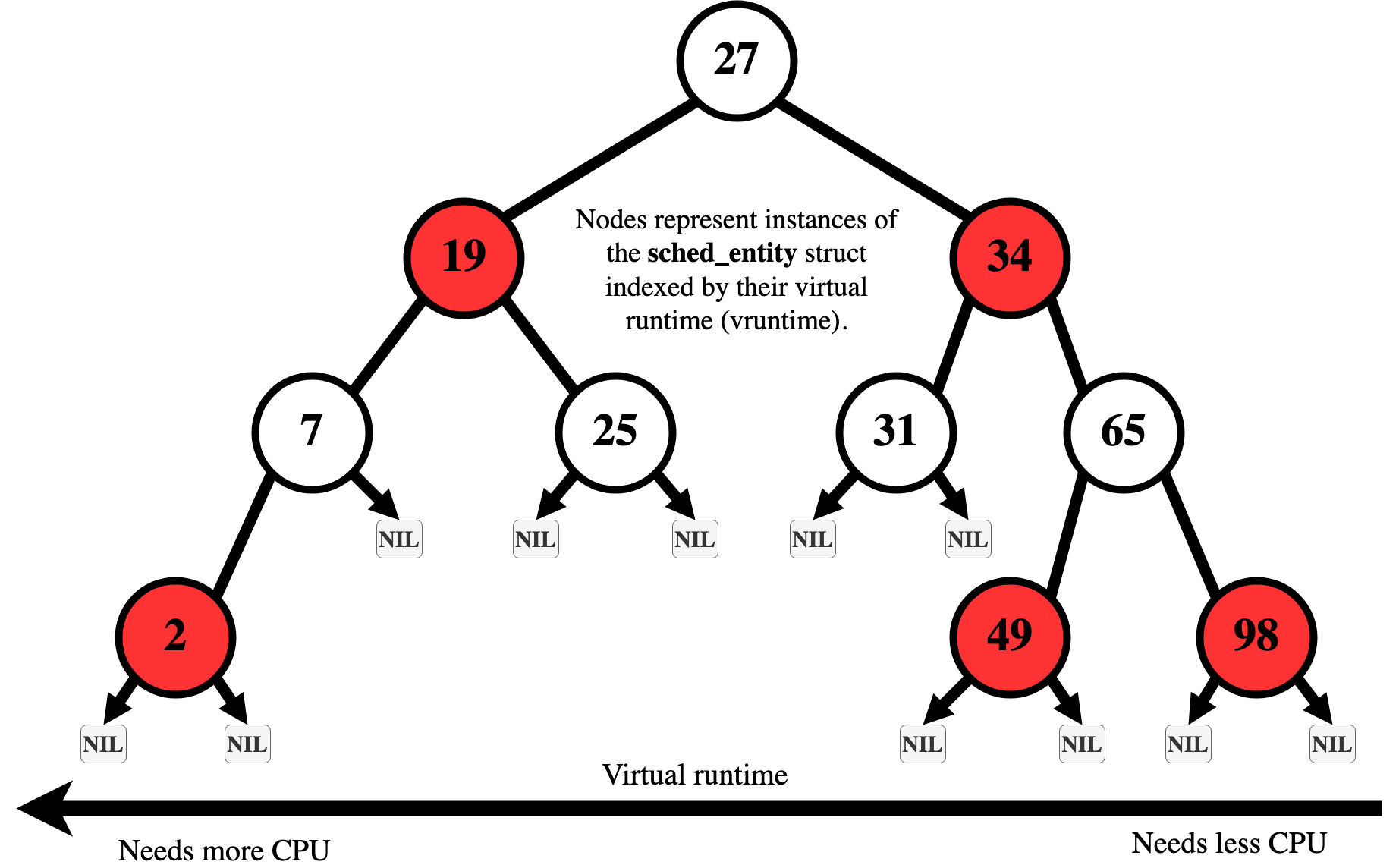
프로세스들은 vruntime에 따라 정렬된 상태를 유지하고, 가장 작은 vruntime인 프로세스 선택
ready 상태의 프로세스들을 관리하기 위해, Red Black Tree 활용
- balanced tree로 프로세스가 많아져도 logN으로 선택가능
- 메모리 기반 자료구조로 빠른 탐색 가능
Detail
-
base_slice_ns
/sys/kernel/debug/sched/base_slice_ns파일을 통해 CPU 점유 시간 단위를 튜닝 가능- low latency가 필요한 desktop 환경과, throughput이 중요한 server 환경에 따라 조정 가능
- 단, CONFIG_HZ 설정에 따라 base_slice_ns < TICK_NSEC일 경우, 큰 효과는 없음
- 이걸 짧게 두면 어떻게 될까요?
- context switching
- 반응속도가 중요한 경우
- 게임 핑을 ms단위
-
Nice / SCHED_BATCH 처리 강화 낮은 우선순위나 배치 작업에 대한 태스크를 훨씬 더 효과적으로 격리 → interactive 작업과 background 작업의 간섭 최소화 IO를 얼마나 잡아먹냐?
-
Scheduling Policies
-
SCHED_NORMAL (또는 SCHED_OTHER) 일반적인 유저 프로세스가 사용하는 기본 정책
-
SCHED_BATCH 선점을 거의 하지 않으며, CPU를 길게 점유하게 함 → 캐시 활용도는 높아지나, 반응성은 떨어짐 → 비인터랙티브한 배치 작업에 적합
-
SCHED_IDLE nice 19보다도 낮은 우선순위를 가지며, 시스템이 idle 상태일 때만 실행됨 → idle timer 기반이 아니며, 우선순위 역전 문제 방지를 위해 단순화됨
-
실시간 정책인 SCHED_FIFO, SCHED_RR는 CFS가 아닌 별도 모듈(sched/rt.c)에서 처리되며, POSIX 명세를 따름.
Convoy Effect는 해결되었나?
하나의 긴 작업(프로세스)이 CPU를 점유하고 있는 동안, 짧은 작업들이 그 뒤에 줄을 서면서 전체 시스템 지연(latency)이 증가하는 현상
-
vruntime 기반 공정한 선점
- CFS는 정적 우선순위나 길이 기반이 아니라, 실제로 얼마만큼 CPU를 사용했는지 vruntime를 기준으로 스케줄링
- CPU를 적게 사용한 작업일수록 먼저 실행됨 → 긴 작업(A)이 CPU를 계속 점유할 수 없음
-
Preemption (선점) 기반 실행
- CFS는 task_tick()에서 현재 실행 중인 태스크가 너무 오래 실행 중이라면 선점
- 즉, 짧은 작업이 runnable 상태가 되면 wakeup_preempt() 로 긴 작업을 선점 가능
-
Nice level / Weight 기반 동적 조정
- 태스크는 nice 값에 따라 가중치(weight) 를 갖고, vruntime 증가 속도에 차등 적용
- I/O bound, 짧은 interactive 작업에 낮은 nice 값을 부여하면 더 자주 CPU 할당
어플리케이션 개발자가 건드릴수 없는 영역
여기서부터 건드릴수잇게 만듬
cpu 스케줄링을 통제할수 잇는 인터페이스의 역할을 한다!
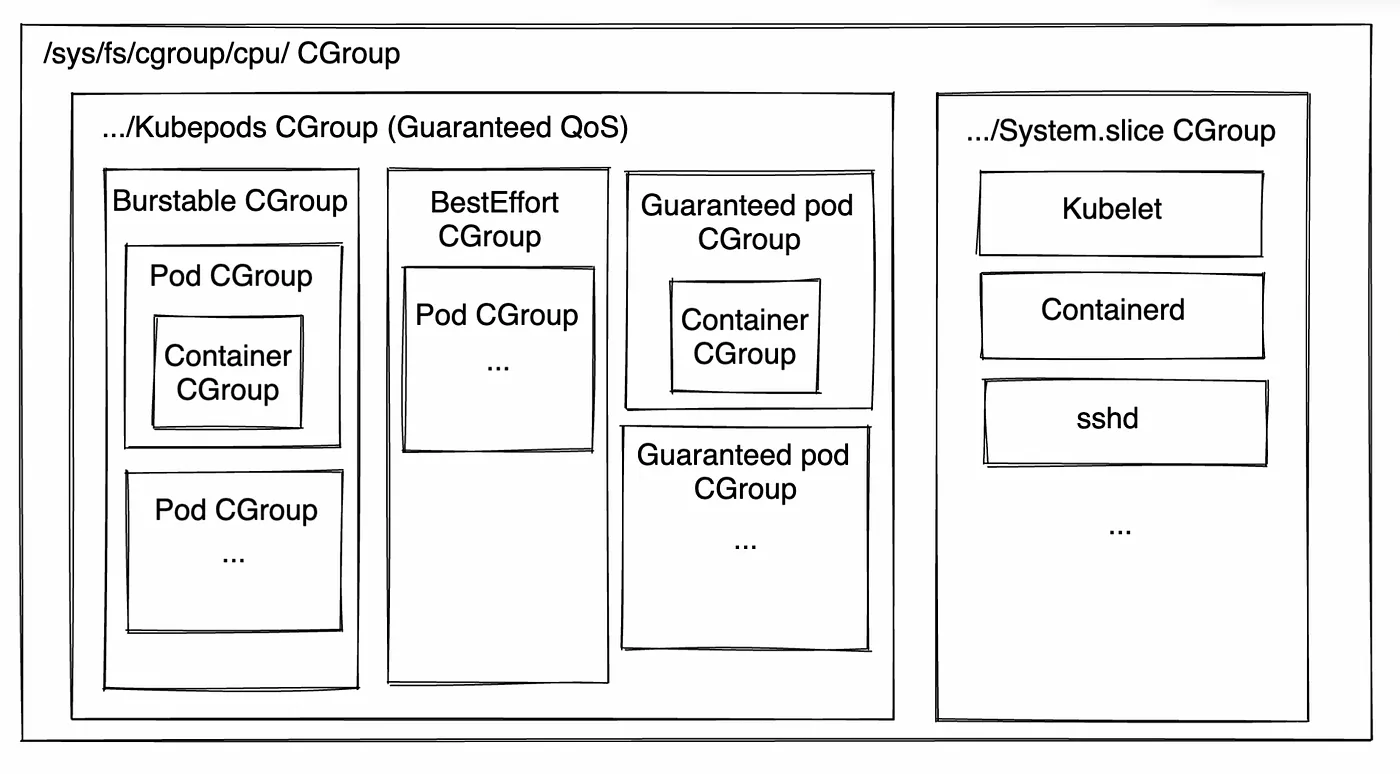
CGroup을 통한 Group Scheduling
docker, k8s 같이 컨테이너 기술에 활용되는 핵심 모듈
control group
- 프로세스에다가 자원을 할당하게 만들어줄수 있어요
- CPU, network IO, memory, disk IO
CFS는 개별 태스크 단위의 공정한 스케줄링뿐 아니라, 태스크 그룹 단위의 공정한 스케줄링도 지원함
- 예: 사용자 A와 B가 각각 여러 개의 프로세스를 실행 중일 때, 사용자 단위로 CPU 점유 시간을 공정하게 분배하고 싶다면?
이를 위해 CFS는 Control Group(cgroup) 기능과 통합되어, 다음과 같은 방식으로 그룹별 스케줄링이 가능
# Cgroup filesystem 마운트 및 초기화
mount -t tmpfs cgroup_root /sys/fs/cgroup
mkdir /sys/fs/cgroup/cpu
mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
cd /sys/fs/cgroup/cpu
# 그룹 생성
mkdir multimedia
mkdir browser
# CPU 점유 비율 설정
echo 2048 > multimedia/cpu.shares
echo 1024 > browser/cpu.shares
# 프로세스를 특정 그룹에 배정
echo <PID> > browser/tasks- cpu.shares는 각 그룹의 CPU 점유 비율을 상대적으로 조절할 수 있는 값
- multimedia 그룹이 browser보다 2배 더 많은 CPU 자원을 가지도록 설정 가능
Multi-core에서도 잘 작동할까?
CFS 스케줄러는 각 CPU 코어마다 독립적인 runqueue(CFS runqueue) 를 유지하며, CPU-process affinity를 고려하여 실행 순서를 결정한다.
하지만 시스템 전체의 자원 활용률을 높이기 위해, CFS는 주기적으로 CPU 간 부하를 비교하고, 불균형 시 태스크를 migrate한다.
rq->cfs.load.weight: 해당 runqueue에 있는 모든 태스크의 정적 가중치(nice 기반) 합계cfs_rq->avg.util_avg: PELT 기반의 CPU 사용률 예측값으로, 실제 부하를 더 정확하게 반영함- CFS의 로드 밸런싱 로직은 두 값 모두를 참조하지만, 커널 버전에 따라 static weight 중심으로 오동작할 수 있다.
https://github.com/torvalds/linux/blob/master/kernel/sched/fair.c#L4597 https://dl.acm.org/doi/10.1145/2901318.2901326
EEVDF Scheduler (Linux 6.6~)
Earliest Eligible Virtual Deadline First
CFS의 공정성 개념을 유지하면서도, 지연(latency) 제어와 예측성 향상을 위해 설계된 새로운 스케줄러. Linux 6.6 커널부터 CFS의 내부 알고리즘을 EEVDF로 대체.
-
virtual deadline 기반 스케줄링 각 태스크에 가상 마감시간(virtual deadline)을 할당하고, 가장 빠른 마감시간을 가진 태스크부터 실행
→ I/O bound, interactive 태스크에 유리
-
CFS의 vruntime 기반 방식보다 latency-aware → 태스크의 응답성을 개선하고, CPU 자원의 배분이 더 예측 가능해짐
-
기존 인터페이스 유지 nice, SCHED_NORMAL, SCHED_BATCH, cgroup/cpu.shares 등 기존 설정 방식은 동일하게 작동
→ 사용자 입장에서는 기존 CFS와의 차이를 거의 느끼지 않음