KVM(Kernel-based Virtual Machine)은 리눅스 커널에 통합된 하이퍼바이저 기능 클라우드 컴퓨팅에서 흔히 사용되는 KVM 기반의 가상 머신은 어떻게 CPU 자원을 활용하고, vCPU는 어떻게 실제 pCPU에 매핑하는지 확인
KVM 구조
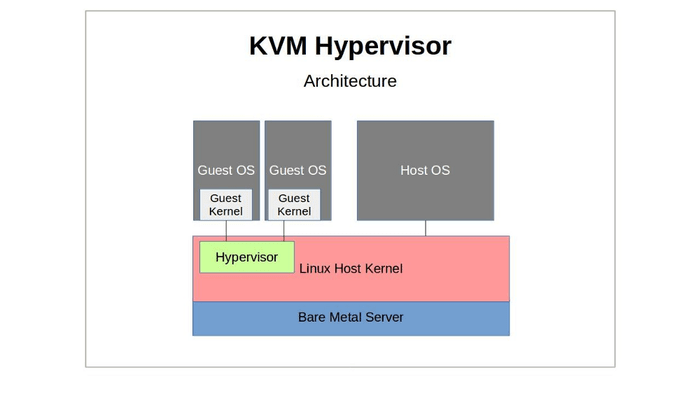
KVM은 리눅스 커널을 그대로 하이퍼바이저로 확장한 구조
기존 리눅스 커널 위에 KVM module을 추가함으로써, 운영체제가 곧 하이퍼바이저로 동작
커널 모듈
커널 모듈(Kernel Module)은 리눅스 커널의 기능을 동적으로 확장할 수 있는 방식 모듈을 통해 커널을 다시 빌드하거나 부팅하지 않고도 새로운 기능(예: 파일시스템, 디바이스 드라이버, 하이퍼바이저 등)을 추가
- 네트워크 카드 드라이버 모듈 (e1000e.ko)
- 파일시스템 모듈 (xfs.ko, nfs.ko)
- KVM 모듈 (kvm.ko, kvm-intel.ko, kvm-amd.ko)
모듈은 커널에 insmod/modprobe로 삽입하고, /proc/modules 또는 lsmod로 확인
QEMU (user space)
- VM의 가상 하드웨어를 구성하는 에뮬레이터
- 가상 NIC, 블록 디바이스, VGA 등 모두 QEMU가 구성 및 관리
- vCPU 실행 요청을 위해 /dev/kvm에 ioctl을 호출하여 KVM 커널 모듈과 통신
- 각 vCPU는 QEMU에 의해 독립적인 유저 스레드(pthread)로 실행
/dev/kvm (인터페이스)
- QEMU ↔ 커널 간 통신 인터페이스
- qemu에서 ioctl로 통신
- KVM_CREATE_VM: 새로운 VM 컨텍스트 생성
- KVM_CREATE_VCPU: vCPU(thread) 생성
- KVM_RUN: 게스트 코드를 실행 (→ VMEnter)
- KVM_GET_REGS, KVM_SET_SREGS: 레지스터 상태 제어
ioctl
ioctl(Input/Output Control)은 유닉스 계열 운영체제에서 디바이스나 커널 객체를 제어하기 위한 시스템콜 일반적인 read/write 인터페이스로는 처리하기 어려운 구조체 기반 명령 전달 등에 사용
ioctl(fd, command, argument) 형식으로 호출되며, 정의된 상수(#define)로 커널과 통신
KVM Kernel Module
- QEMU에서 전달받은 vCPU를 실제 커널 스레드로 등록
- VMCS(Virtual Machine Control Structure) or VMCB(x86/ARM 등)에 컨텍스트 저장
- VM 실행 중 VMExit이 발생하면, 다시 QEMU로 제어 반환
Linux Scheduler
- 리눅스 CFS(Completely Fair Scheduler)가 vCPU thread를 일반 커널 스레드와 동일하게 스케줄링
- 즉, 하나의 vCPU는 host의 커널 스레드 = struct task_struct 로 표현됨
- 이 때문에 NUMA, priority, pinning, cgroup 등이 모두 적용 가능
Device I/O
가상 머신 내부에서의 네트워크 패킷 송수신, 디스크 읽기/쓰기와 같은 I/O는 대부분 QEMU가 에뮬레이션 및 전달
KVM은 CPU 가상화에 집중하며, I/O 처리 로직은 QEMU가 담당
네트워크 (virtio-net 등)
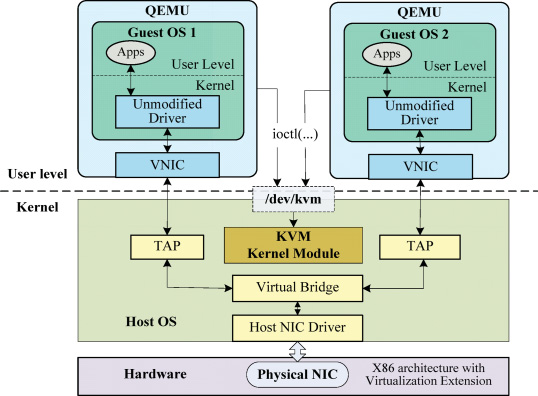
- 게스트 OS는 eth0 같은 가상 NIC를 통해 패킷을 전송
- 이 NIC는 QEMU가 virtio-net, e1000 등으로 에뮬레이션하며,
- 호스트 측에서는 TAP 인터페이스를 통해 외부 브리지(br0)나 SDN(Open vSwitch)로 전달
스토리지 (virtio-blk, qcow2 등)
-
게스트 OS는 /dev/vda와 같은 디바이스를 통해 블록 스토리지를 접근
-
QEMU는 이를 .qcow2나 .raw 파일로 매핑하고, 실제 I/O를 수행
-
고성능 환경에서는 virtio-blk, vhost-user, io_uring을 이용해 오버헤드를 줄일 수 있음
virtio란?
Paravirtualized I/O를 위한 표준 인터페이스 일반적인 에뮬레이션 방식보다 호스트-게스트 간 I/O 병목을 줄이고 CPU 효율을 높이기 위한 기술 대표적으로 virtio-net, virtio-blk, virtio-scsi, virtio-rng 등
vCPU(Virtual CPU)
- VM 입장에서는 독립적인 CPU처럼 보임
- 실제로는 호스트의 쓰레드로 동작함 (
pthread) KVM_RUNioctl 호출을 통해 게스트 코드를 실행하다가 VM Exit 시 돌아옴
Key Feature
- 1 vCPU = 1 host thread (by QEMU)
- 게스트 OS에서는 SMP 시스템처럼 동작하지만, 실제로는 각각의 vCPU가 호스트 스레드로 구현되어 동적으로 pCPU 위에서 실행
- 스케줄링, 인터럽트, 타이머 등은 모두 호스트 커널 레벨에서 처리됨
vCPU → pCPU 스케줄링
vCPU는 커널에서 관리하는 일반적인 커널 스레드와 동일하게 취급됨 → 즉, CFS Completely Fair Scheduler가 vCPU를 포함한 모든 프로세스를 공평하게 스케줄링
vCPU 스케줄링 특징
| 항목 | 설명 |
|---|---|
| 스케줄링 단위 | host thread (즉, vCPU) |
| 우선순위 | 일반 task와 동일하게 CFS 기준 |
| preemption | 가능함 (vCPU 실행 중에도 커널이 context switch) |
| NUMA awareness | 기본은 없음 → taskset, numactl, cgroup 설정 필요 |
| pinning | 특정 pCPU에 고정 (static affinity 가능) |
고려사항
Double Scheduling
- 게스트 내부에서도 자체적인 CFS 스케줄링이 존재
- → host와 guest에서 모두 스케줄링 발생 → 불필요한 latency/straggler 유발 가능
Steal Time
- 게스트 OS는 vCPU가 사용 중인 줄 알지만, 실제로는 host에서 pCPU를 잃었을 경우 → 이 시간은 게스트 입장에선 ‘실행 중’처럼 보이지만, 다른 스레드에 밀려 대기한 시간
/proc/stat의 steal 항목 또는top의%st로 확인 가능
SMT/stacked core 문제
- 동일한 물리 코어의 sibling(vCPU1, vCPU2)이 동시에 스케줄되면 → 성능 간섭 → NUMA-aware + SMT-aware 스케줄링이 중요
NUMA
**NUMA(Non-Uniform Memory Access)**는 멀티코어 시스템에서 CPU와 메모리 사이의 접근 속도가 균일하지 않은 아키텍처
- 시스템은 여러 개의 **메모리 노드(memory node)**와 CPU 노드로 구성
- 각 CPU는 자기 노드(local)의 메모리에 접근할 때는 빠르지만, 다른 노드(remote)의 메모리에 접근할 때는 더 느림
- **메모리 접근 지연(latency)**이 위치에 따라 달라지므로, 자원 배치가 매우 중요
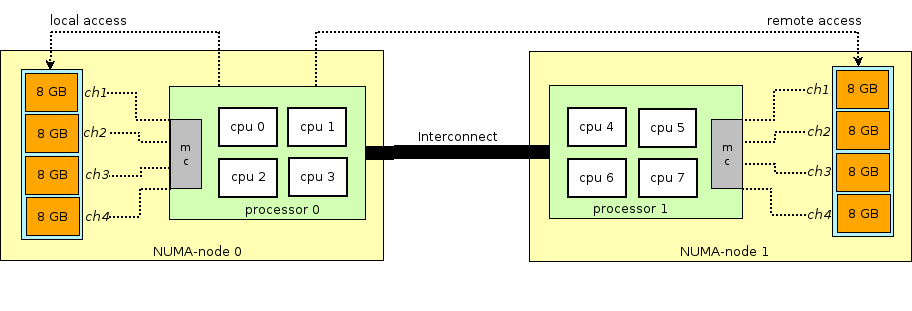
- 물리 서버는 여러개의 CPU 소켓을 가지고 있고 각 소켓에 연결된 memory bank를 가짐
Overcommit
- vCPU 수 > pCPU 수인 경우 성능 예측 어려움
- 예: pCPU 4개인 시스템에 vCPU 10개 할당 → I/O Wait 증가, context switching 비용 증가
레퍼런스
- KVM virtio – redhat.com
- KVM Documentation – kernel.org
- Linux CFS Scheduler Explained
man taskset,man numactl,perf,trace-cmd