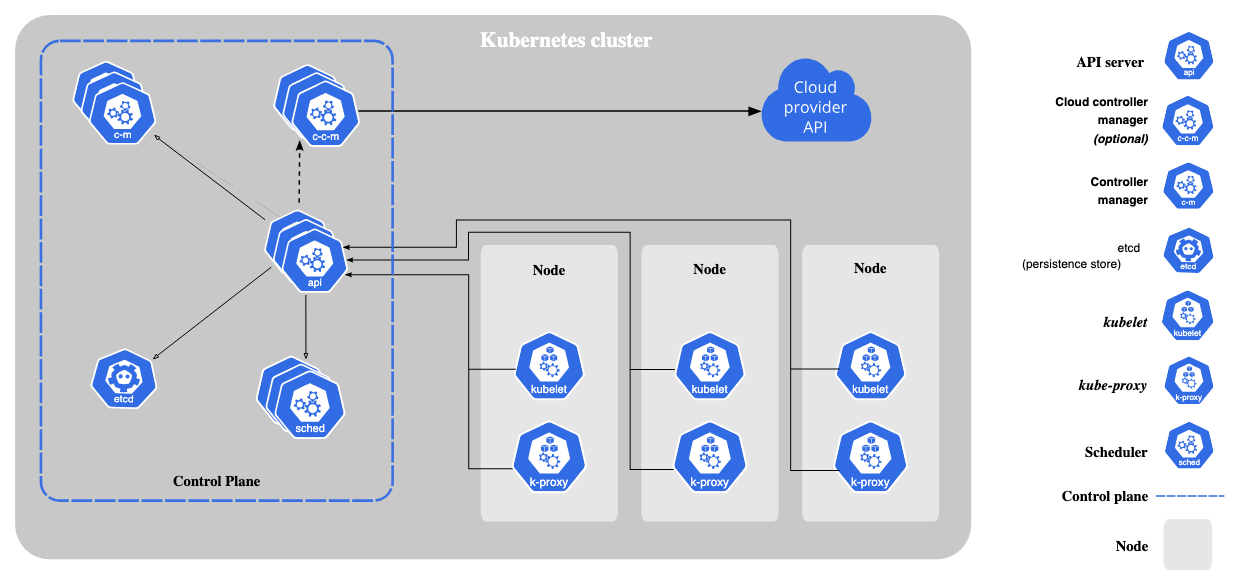
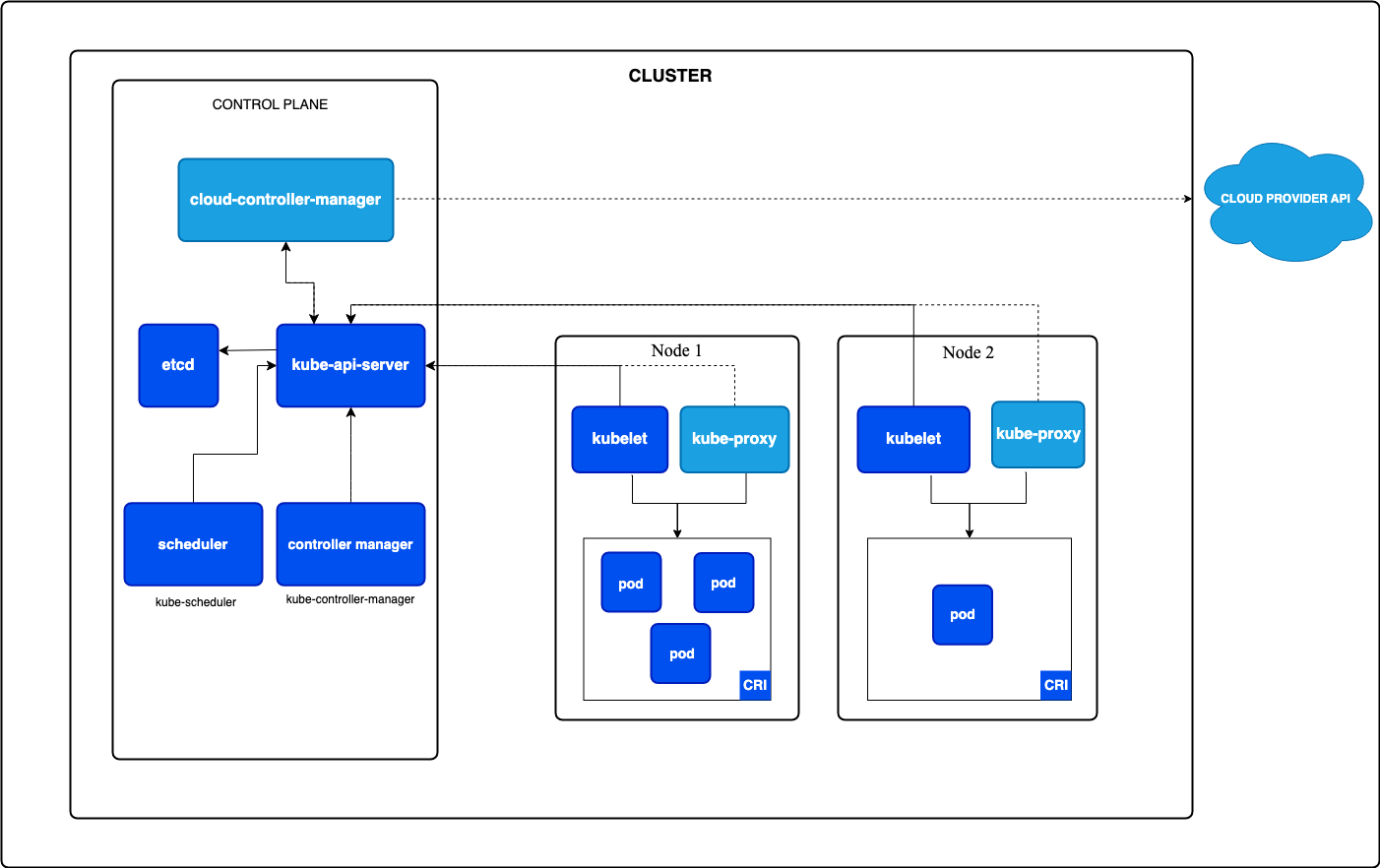
Control Plane
클러스터를 관리하는 역할을 수행하며, worker노드에서 실행되는 pod들을 관리, 조정, 감시하는 컴포넌트들로 구성
각 components들은 다른 host들에 배치될 수는 있으나, 관리포인트와 병목 가능성을 위해 하나의 전용 호스트에게 전담한뒤, 해당 노드에는 container를 띄우지 않게하는 것이 좋음
Why? container가 cpu와 memory를 물리적으로 격리하는 것이 아니기 때문에, core component에도 영향을 줄 수 있음
kube-apiserver
Kubernetes의 endpoint. 모든 요청은 API 서버를 통해 이루어짐 (kubelet, kubectl이 해당 api server와 통신)
해당 component는 수평적으로 확장 가능하게 설계되어서, 여러 호스트에서 구동하는 것이 가능함 (해당 경우에는 LB를 앞에서 두어 로드밸런싱)
etcd
key value store로 주로 cluster의 데이터들을 저장함 (Pods, ConfigMaps, Secrets, Deployments, Nodes 등)
etcd도 kube-apiserver와 마찬가지로 HA 구성이 가능함
kube-scheduler
새로 생성된 pods들을 감시하며, 비어있는 worker node들을 확인하고, pod를 배치하는 역할을 수행함
scheduler factor들은 여러가지가 존재하는데,
- 자원 사용량 (CPU, 메모리)
- 노드 상태 / 제약 조건 (taints, tolerations, affinity/anti-affinity)
- 데이터 지역성 (Pod와 데이터의 위치 근접성)
- 커스텀 스케줄링 정책 (ex. GPU, 레이블 기반 배치)
스케줄러는 단순히 노드를 선택만하고, 실제 실행은 kubelet이 담당
kube-controller-manager
클러스터를 제어하는 프로세스
여러가지 controller 프로세스들이 존재하나, 하나의 binary로 컴파일되어 single process로 수행
다음과 같은 controller들이 있음
- Node controller : node들의 상태들을 확인하고 대응함 ex)노드 다운시, pod 재스케줄링
- Job controller : job resource 실행 및 완료 제어
- Replication Controller: 파드 개수 유지
- ServiceAccount controller : 서비스 계정과 API 접근 토큰 관리
단일 프로세스로 수행되기에 multi host에서는 leader election으로 하나의 primary만 동작
cloud-controller-manager (optional)
클라우드 환경에서만 활용되는 컨트롤러
노드 관리, LB 서비스 프로비저닝, PV 프로비저닝 등을 제공함
각 클라우드 벤더별로 구현체들은 모두 다름 다만 cloud native 환경을 제공하기 위해, 동일한 interface 제공
Node
워커 노드는 실제 container가 실행되며, control plane의 요청을 받아 pod 생성 및 삭제와 network 연결을 수행
kubelet
각 노드의 agent로 kube-apiserver와 통신하며 해당 노드에 할당된 pod를 실행함
동시에 pod monitoring, container health check도 수행
컨테이너 실행시, container runtime를 통해 수행
kube-proxy (optional)
클러스터의 네트워크를 연결하는 component
Service 리소스를 기반으로 Pod간 트래픽을 로드밸런싱을 수행함 내부적으론 os의 iptables, eBPF로 네트워크 제어 수행
CNI 플러그인(Cilium, Calico)을 사용하면 대체 가능
Container runtime
실제 컨테이너 실행 및 lifecycle 관리
CRI-O, containerd 가 주로 사용되고, docker는 1.20 버전부터 지원하지 않음