- 금주 수행한 내용
-
OpenSearch based
Faiss HNSW 인덱싱로직 분석- 벡터 인덱싱 시 그래프 구조가 디스크에 저장되며, 검색 시 메모리에 적재되는 방식 확인
- 인덱싱 및 검색 시 파라미터가 메모리 사용량과 검색 성능(latency, accuracy) 직접적인 영향을 미침을 확인함
m: 각 노드가 유지하는 연결(edge)의 수 → 높을수록 recall 상승, 메모리 사용 증가ef_construction: 인덱싱 시 그래프 탐색 폭 → 인덱스 정확도 상승, 인덱싱 시간 증가ef_search: 검색 시 탐색 범위 → 높을수록 정확도 상승, latency 증가dimension: 그래프 노드에 해당 벡터 값 저장 → 높을수록 메모리 사용량 증가
- 인덱싱 파라미터 (
m,dimension) 가 메모리 사용량에 미치는 영향 분석- 노드 하나당 메모리 사용량 근사 :
(d * 4 + M * 2 * 4) bytes - d(Dimension size) * 4(float type size)
- M(neigbor count) * 2(bidirectional edge) * 4(node address size)
- d = 1024, M = 16, nodes: 1.7M
- (1024 * 4 + 16 * 4 * 2) * 1.7M (bytes) ~= 7.1808 GB
- 노드 하나당 메모리 사용량 근사 :
-
Production 환경에서 vector DB serving시, 고려해야하는 요소 확인
- 실서비스 환경에서의 주요 고려 사항 파악
-
벡터 인덱스의 메모리 상주 여부
Faiss HNSW 알고리즘의 경우 그래프 정보만을 메모리상에 올려놓고 search 진행 -
production 샤딩 전략 및 부하 분산 production 환경에서는 고가용성을 보장하기 위해, 멀티노드 샤딩 전략을 사용 최소한의 가용성을 보장하기 위해
shard count = node count,replica = 1을 사용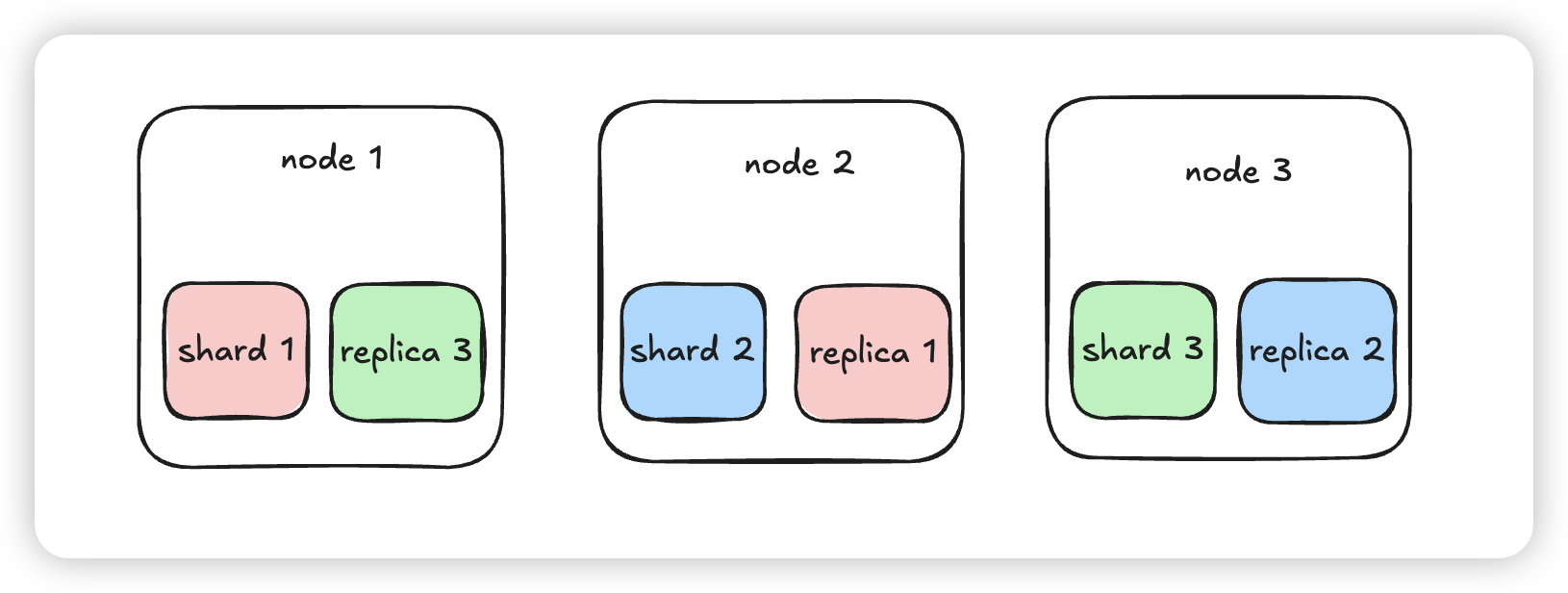 이 때, replica에도 primary shard의 index 정보를 copy하기에 knn index 메모리를 두배로 사용 (alwaysLoadKnnIndex default true)
이 때, replica에도 primary shard의 index 정보를 copy하기에 knn index 메모리를 두배로 사용 (alwaysLoadKnnIndex default true)실제 production 환경에서 총 indexing memory만 15GB 필요
-
Document embedding시 chuncking
- embedding model의 input size 및 맥락을 위해 문서를 쪼개는 chunking 과정 진행
- 때문에 하나의 문서당 여러개의 벡터로 표현 → vector 갯수 증가 → 메모리 사용 증가
-
- 실서비스 환경에서의 주요 고려 사항 파악
- 내주 수행할 내용
- vectorDB HNSW 인덱싱 메모리 이슈 문제 실험 및 수치화
- HNSW 그래프가 메모리에 상주해야 하는 구조적 특성으로 인한 서비스 상의 문제점 정리
- 예상 시나리오:
- 다수의 샤드/노드에 대용량 벡터 인덱스를 분산 배치했을 때의 메모리 소비 패턴
- 실험 계획:
- 벡터 개수, dimension, 파라미터별 메모리 사용량 및 검색 latency 수치화
- 벡터 수 증가에 따른 메모리 사용량 곡선 도출 (e.g., 1M, 10M, 100M vectors)
- 해결 방안 서치
- vector qunatization으로 가능한가?
- disk based indexing으로 해결 가능한가?
참고 논문: https://arxiv.org/abs/2405.03267 https://proceedings.neurips.cc/paper_files/paper/2019/file/09853c7fb1d3f8ee67a61b6bf4a7f8e6-Paper.pdf