질문#1) Milvus를 사용했나요? VM 노드 세개에 deploy를 한 것 같은데, FAISS를 어떻게 사용했는지, 알려주세요.
문서들의 lexcial search도 필요하여, OpenSearch (Elastic Search fork)를 활용했었습니다.
clustering을 통해
- 3 manger nodes(c6g.large.search, 2vCPU, 4GB)
- 3 data nodes(m7g.xlarge.search, 4vcpu, 16GB)
AWS OpenSearch 솔루션으로 해당 cluster 관리를 했습니다.
plugin으로 faiss, lucene, nmslib 등 vector search engine을 지원하여 이 중 faiss를 사용했습니다.
질문#2) Index build 시간도 궁금합니다.
Index를 생성(build)하는 시간 자체는 거의 걸리지 않았습니다.
다만 기존 이미 생성된 Index의 세팅을 변경 시(샤드 개수, hnsw 파라미터 수정)에는 reindex를 진행어야 했고, 이는 기존 index에서 copy하는 방식으로, 같은 수의 insert와 거의 동일한 시간이 걸렸습니다.
질문#3) Index build가 된 이후, CRUD 연산 시간 - Create: 새로운 embedding 추가시 걸리는 시간 - Update: Document가 업데이트 된 경우 embedding이 바뀌면, Index rebuild? 를 하는지, 한다면, 걸리는 시간 - Delete: 위와 동일한 시간
해당 production 환경에 접근이 불가능해서 local에서 재현했습니다.
금주 수행한 내용
vectorDB HNSW 인덱싱 메모리 이슈 문제 실험 및 수치화
HNSW 그래프가 메모리에 상주해야 하는 구조적 특성으로 인한 서비스 상의 문제점 정리
Env
production 환경과 비슷한 local 실험 환경 재구성
OpenSearch cluster (3 node)
- 호스트에 3개의 container로 opensearch cluster 생성
- Host : 11 core, 36GB
- 1.2M document Indexed
Metric
- cpu usage (1분간 점유한 코어 개수 평균)
- virtual memory
- rss (physical memory allocated)
- file IO
Index Create
"embedding": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {
"ef_construction": 128,
"m": 16
}
}
},Document Insert (20만개 삽입)
- 임베딩된 문서를 삽입하는 task 제출 이후 cluster 상태 확인
Search
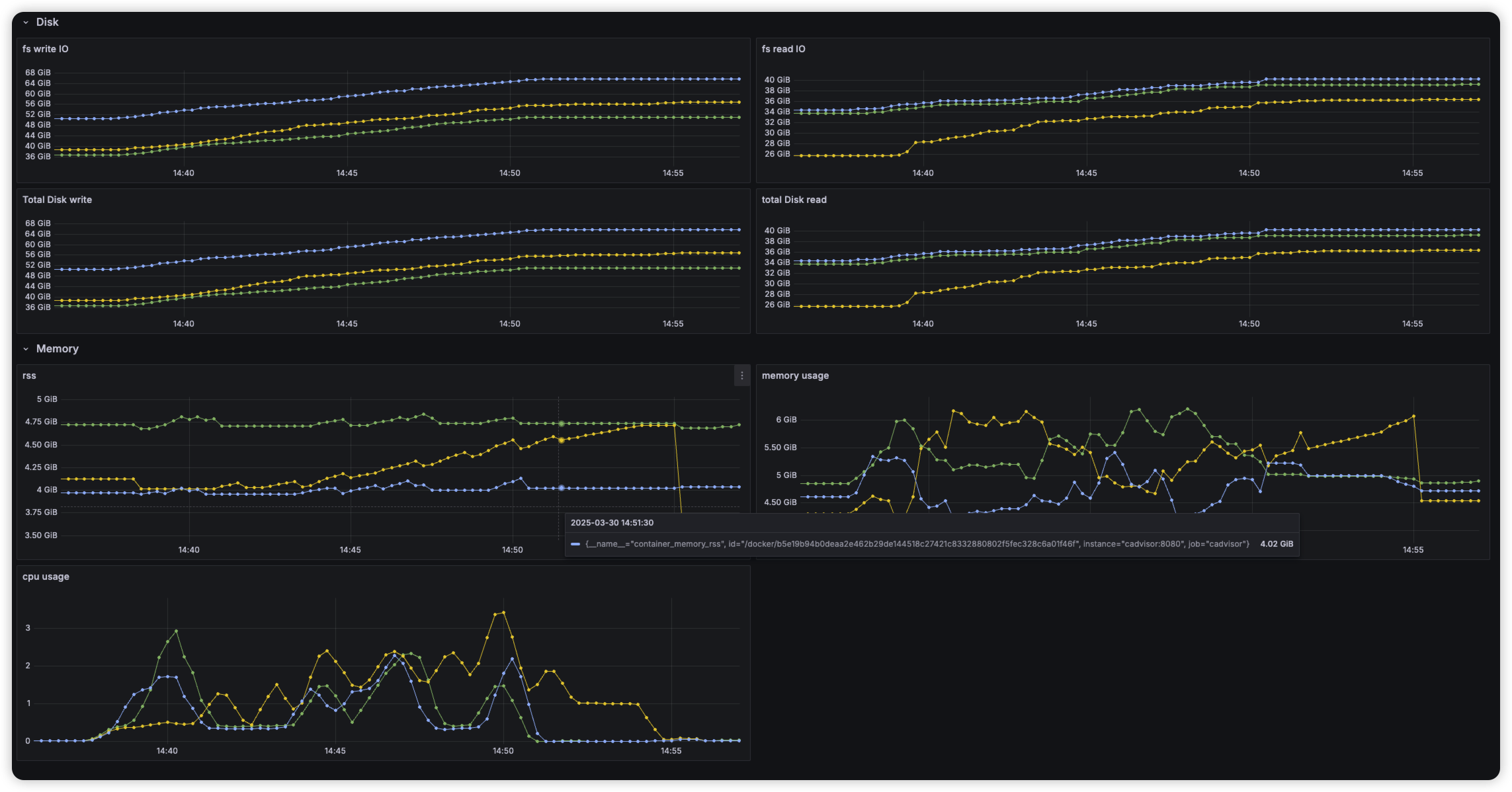
- 문서 삽입 이후, topk 100 query시에 latency 및 노드 모니터링
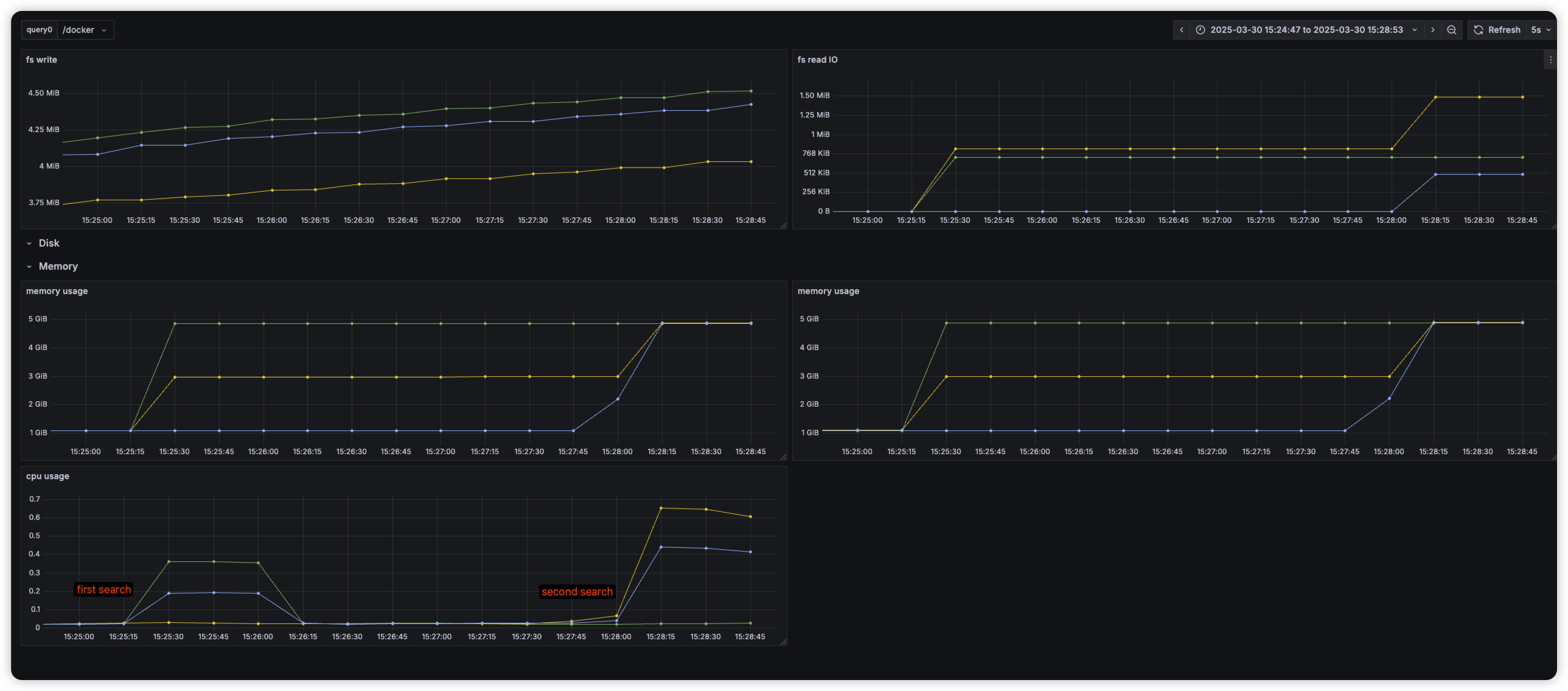 문서 삽입 이후 HNSW 인덱스가 바로 메모리에 올라오지 않고 file 형태로 저장 확인
이후 요청시, memory 올려 놓아 cold start 발생
문서 삽입 이후 HNSW 인덱스가 바로 메모리에 올라오지 않고 file 형태로 저장 확인
이후 요청시, memory 올려 놓아 cold start 발생
first search latency

Second Search latency

Warm up
Index에 있는 hnsw graph를 메모리에 올려 놓아, search 요청 시 바로 처리하도록 함
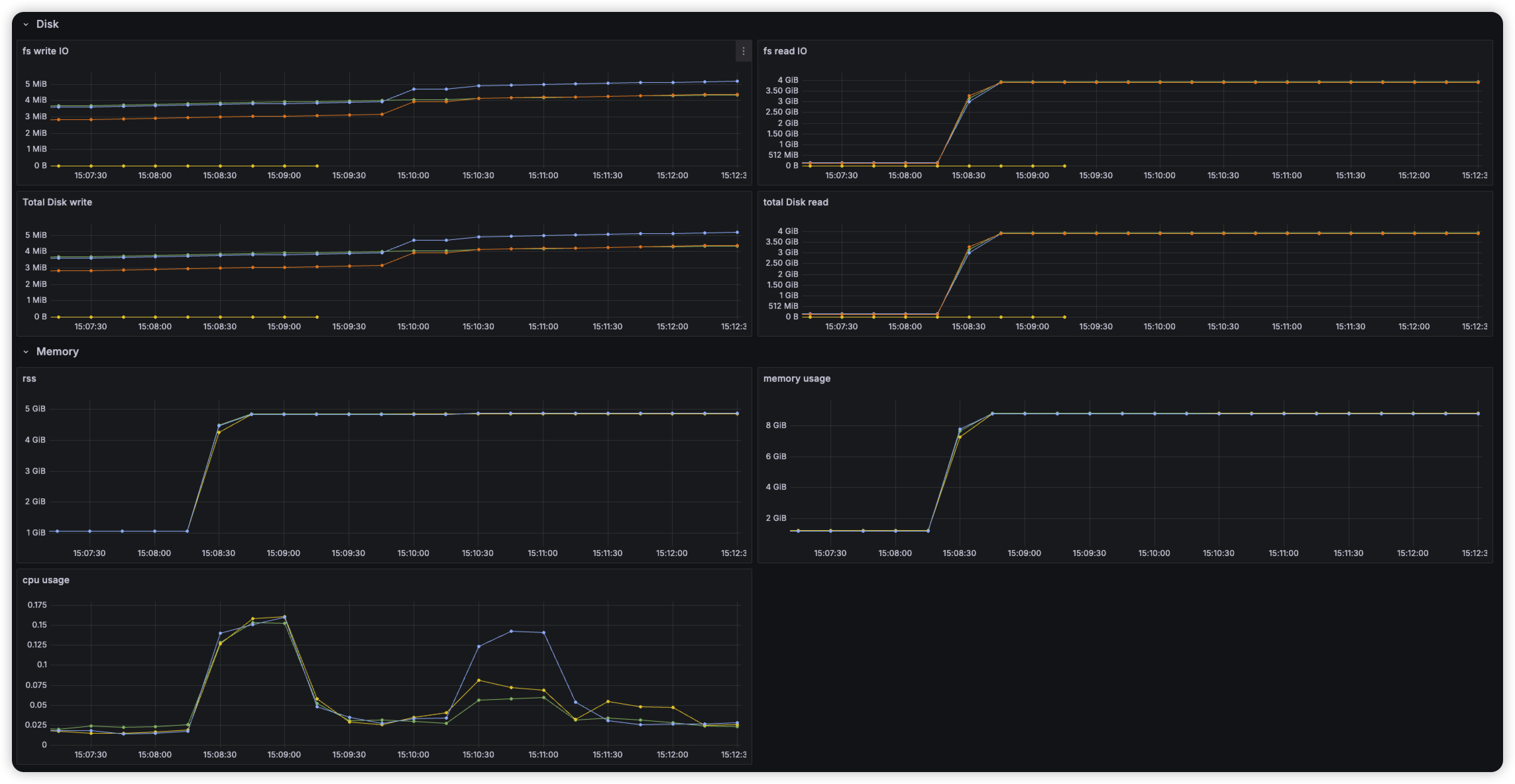
warm-up 요청 시, 노드당 3.5GB의 인덱스를 메모리에 올려놓는 것을 확인
After warm-up

이슈
- 반복적으로 메모리에 index load, store시 JVM GC 작동
2025-03-30 17:41:11 opensearch-node3 | [2025-03-30T08:41:11,213][INFO ][o.o.m.j.JvmGcMonitorService] [opensearch-node3] [gc][130] overhead, spent [708ms] collecting in the last [1.7s]
- 샤드 재분배 작업 샤드간 비슷한 크기를 갖도록 유지하는데, node의 상태에 따라 간혹 불균일한 샤드를 갖게될 경우 이를 재할당 함
GET _list/shards/target-index
target-index 0 r STARTED 238002 5.3gb 172.23.0.3 opensearch-node3
target-index 0 p STARTED 238002 5.3gb 172.23.0.5 opensearch-node1
target-index 1 r STARTED 238174 5.3gb 172.23.0.3 opensearch-node3
target-index 1 p STARTED 238174 5.3gb 172.23.0.4 opensearch-node2
target-index 2 r STARTED 238053 5.3gb 172.23.0.3 opensearch-node3
target-index 2 p STARTED 238053 5.3gb 172.23.0.5 opensearch-node1
target-index 3 r STARTED 238743 5.3gb 172.23.0.3 opensearch-node3
target-index 3 p RELOCATING 238743 5.3gb 172.23.0.5 opensearch-node1 -> 172.23.0.4 UnHMdjXFREi63---U6yhEA opensearch-node2
target-index 4 r STARTED 238772 5.3gb 172.23.0.5 opensearch-node1
target-index 4 p STARTED 238772 5.3gb 172.23.0.4 opensearch-node2
target-index 5 p STARTED 239197 5.3gb 172.23.0.5 opensearch-node1
target-index 5 r STARTED 239197 5.3gb 172.23.0.4 opensearch-node2
next_token null
이 때, 많은 File IO 및 메모리 부하 확인
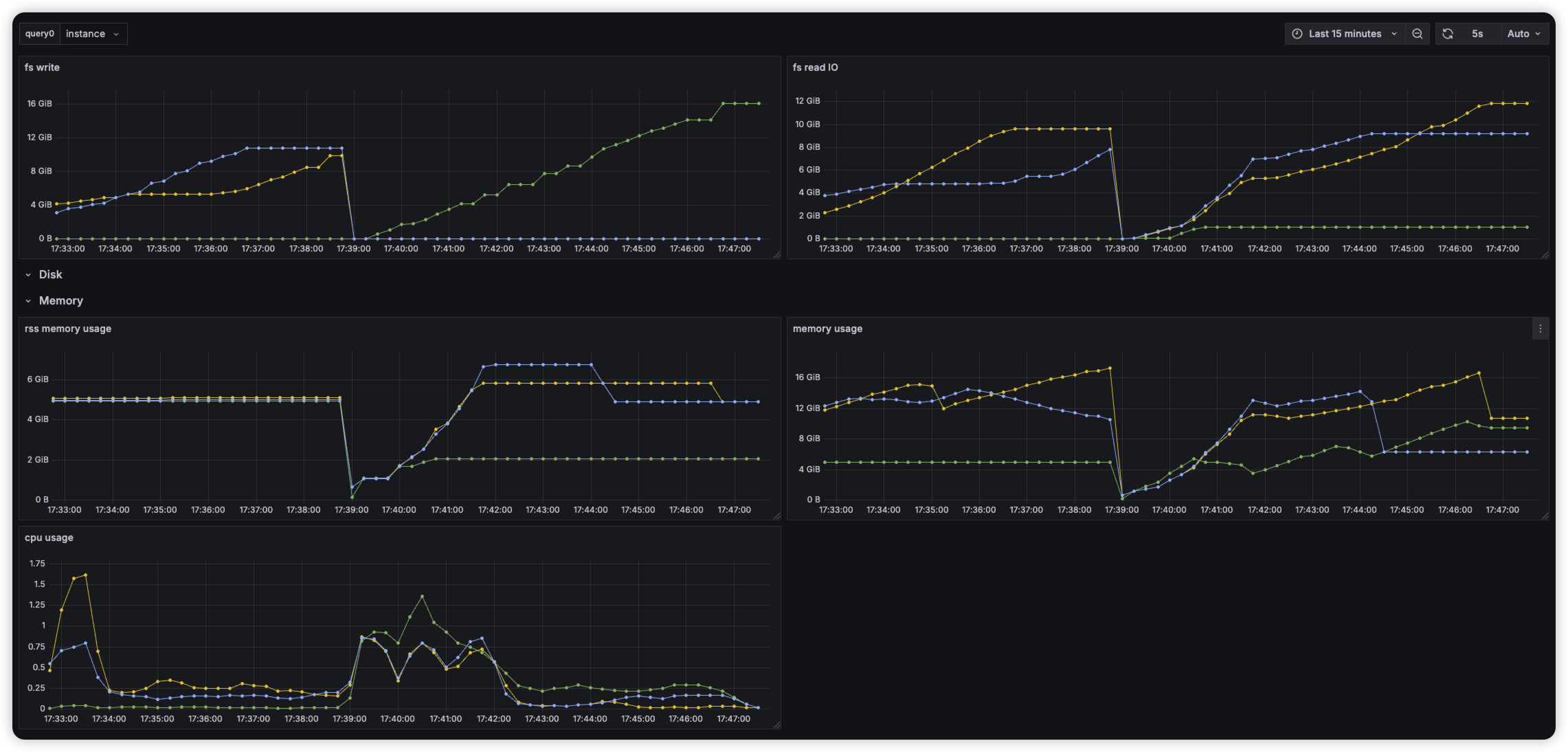
Insight
- local 환경이라 disk → memory로 로드가 빠를텐데, cloud 환경이라면 이과정이 상당히 오래걸리지 않을까?
- cloud 기반 DB들은 대부분 EBS 스토리지를 사용할텐데, 이는 실시간 서비스를 구축하기엔 latency가 너무 길지 않을까?
- 특히나 vector search(HNSW)의 구조상 인덱스에 저장하는 크기가 너무 빠르게 증가함
내주 수행할 내용
- 반복적인 인덱스 memory load, store이 다른 VectorDB solution(Milvus) 혹은 vector engine(faiss)에도 적용이 되는지 확인
- HNSW를 제외한 다른 ANN 알고리즘에서 해당 문제를 어떻게 접근하는지 확인
- disk based indexing으로 해결 가능한가? https://arxiv.org/abs/2310.00402