금주 수행한 내용
OpenSearch에서 Indexing시 메모리 이슈 수치화
production 환경에서 발생했던 이슈를 local에서 재현하며 문제점 확인
- 인덱싱 시, 많은 Disk I/O 발생 확인
인메모리 구조의 HNSW 알고리즘 특성상 Search, Indexing 시 메모리에 그래프 자료구조를 모두 올려야 함
OpenSearch의 경우 JNI를 통해 C++로 구현된 faiss 이용 faiss에는 HNSW 인덱스를 file로 write,read하는 Interface 제공
void write_index(const Index* idx, const char* fname, int io_flags = 0);
void write_index(const Index* idx, FILE* f, int io_flags = 0);
void write_index(const Index* idx, IOWriter* writer, int io_flags = 0);해당 인터페이스를 통해 많은 File IO가 발생하는 것을 확인
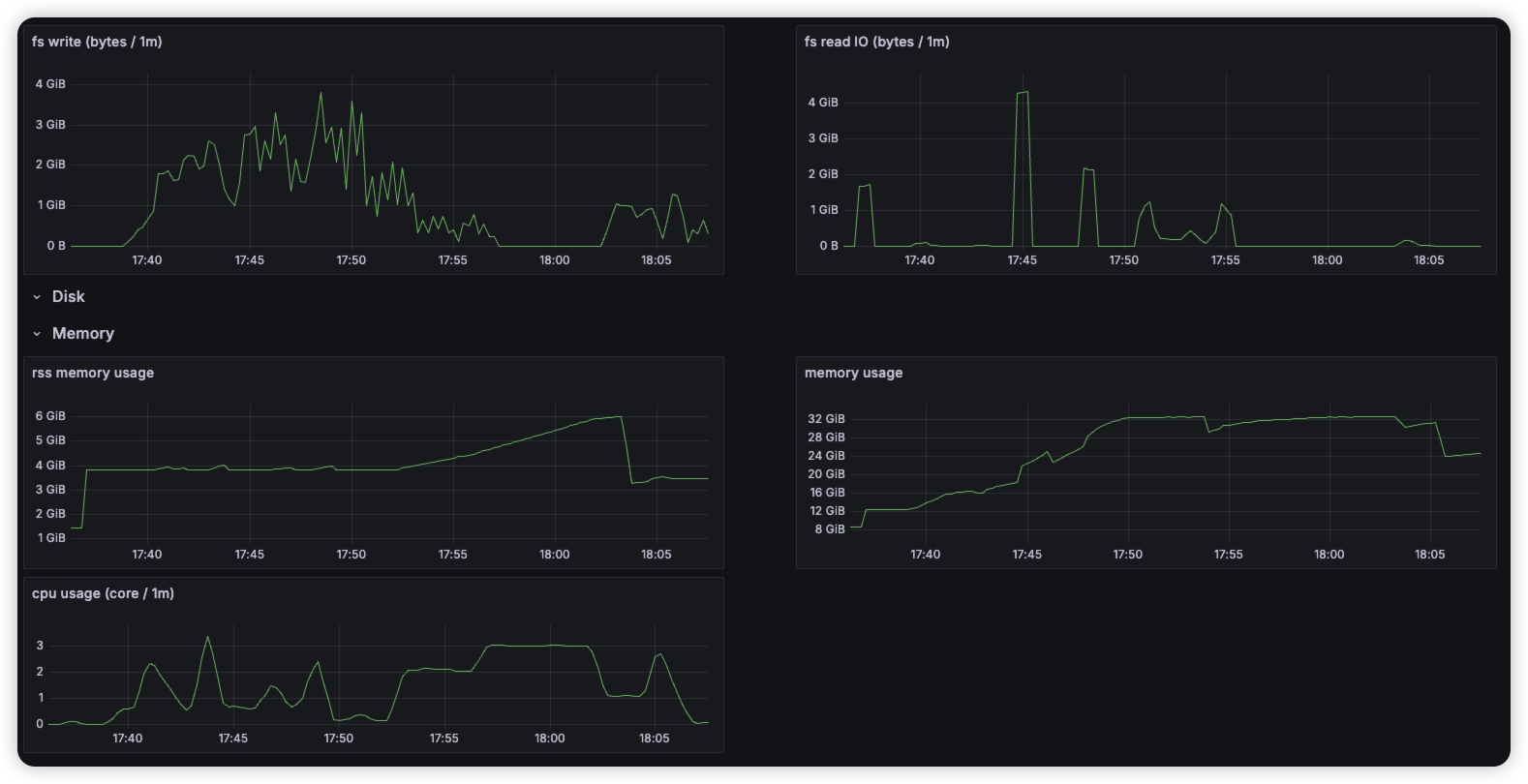
- 해당 실험은 볼륨을 MVME으로 사용
클라우드 서비스에서의 VectorDB
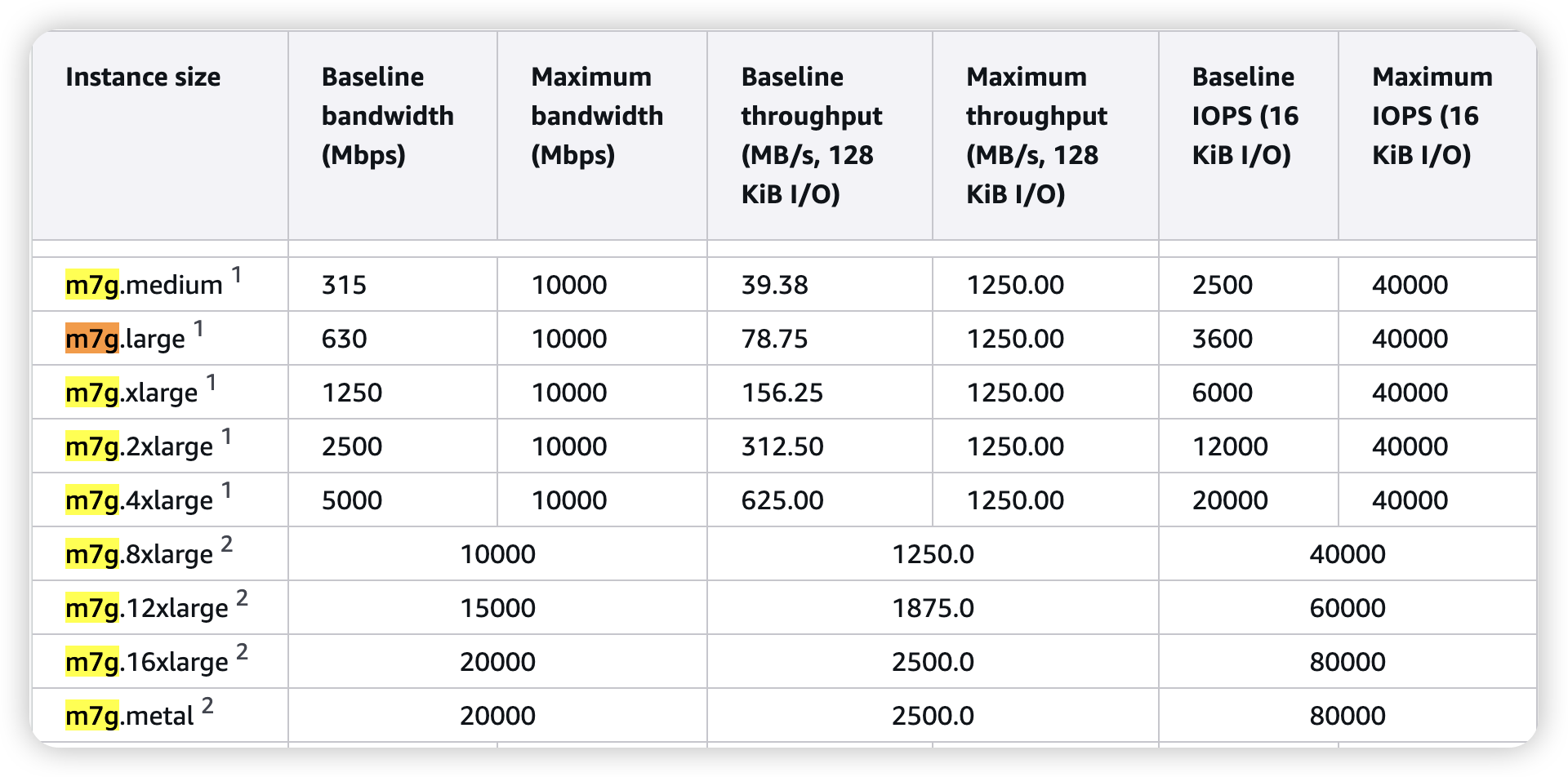

OpenSearch Instance에 AWS EBS를 볼륨을 붙여서 문서들과 Index를 함께 disk에 저장
- 문서 : 큰 용량, 적은 확률로 접근
- 인덱스 : 상대적으로 작은 용량, 잦은 memory to disk load, flush → 병목 예상가능
이를 분리하여 인덱스만 NVME 에 저장하는 것은 불가능
그렇다고 EBS가 아닌, io1 를 붙여서 문서와 함께 저장하는 것은 비효율적임
내주 수행할 내용
- cloud disk latency 실험
- 볼륨으로 많이 사용되는 AWS EBS gp3가 정말 병목일까?
- 가설 확인
- 인덱스를 disk에 바로 write하지 않고
redis같은 별도의 캐시 저장소를 둔다면?- index를 segment로 나눠서, key-value store를 따로 둔다면?
- DPU를 통해서 file cache처럼 쓸 수 있지 않을까?
- 인덱스를 disk에 바로 write하지 않고