보통 캐시를 어디에 사용해야할까?
- memory 계층적 접근 비용이 큰 곳
- 동일 접근 데이터가 빈번할 때,
- read-heavy한 workload가 많을 때,
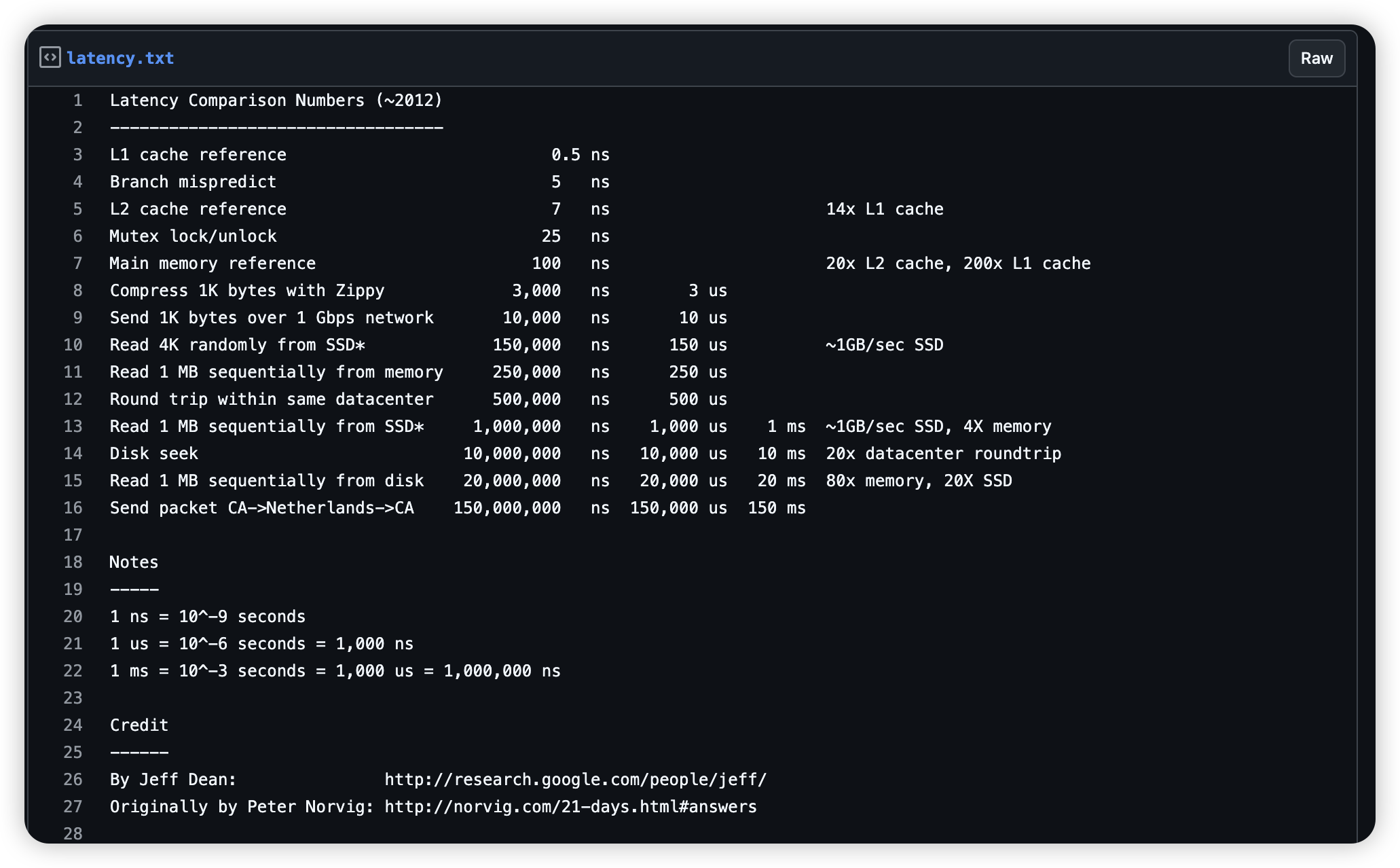 https://gist.github.com/jboner/2841832#file-latency-txt
https://gist.github.com/jboner/2841832#file-latency-txt
캐시를 적용한 모든 부분을 찾아보자
hardware
- CPU L1, L2, L3 cache
- L1, L2 (core 당 instruction, data (memory에서 가져온 애들))
- L3 core 공유하는 캐시들
- physical address cache (TLB)
- virtual memory → physical translate cache
OS
- filesystem page cache
- OS에서 자체 캐시하는 것!
- file read() → file → fs → disk (block page) 가져오는 것들을 캐시해둠!
- Buffer cache / dentry cache / inode cache
DB
- DBMS Buffer Pool
- adaptive hash index
Application
- in-memory storage (Redis, Memcached)
- browser cache
Network
- CDN
- DNS resolve
- ARP
- TLS
- HTTP reverse proxy cache
이 중에서 서비스레벨에서 알아야하는 캐시들과, 어떤 데이터들을 퇴출시킬지 알아보자 (캐시에 모든 데이터를 담을 수 없기에)
TLB
TLB가 필요한 배경
운영체제는 VM을 통해서 프로세스간 메모리 공간을 격리하고 프로세스가 물리적인 메모리를 모두 사용할 수 있는 것처럼 제공 하지만 프로세스는 메모리에 접근하기 위해 page table로부터 physical address를 찾아와야함 (메모리 접근 overhead)
MMU (memroy management unit)
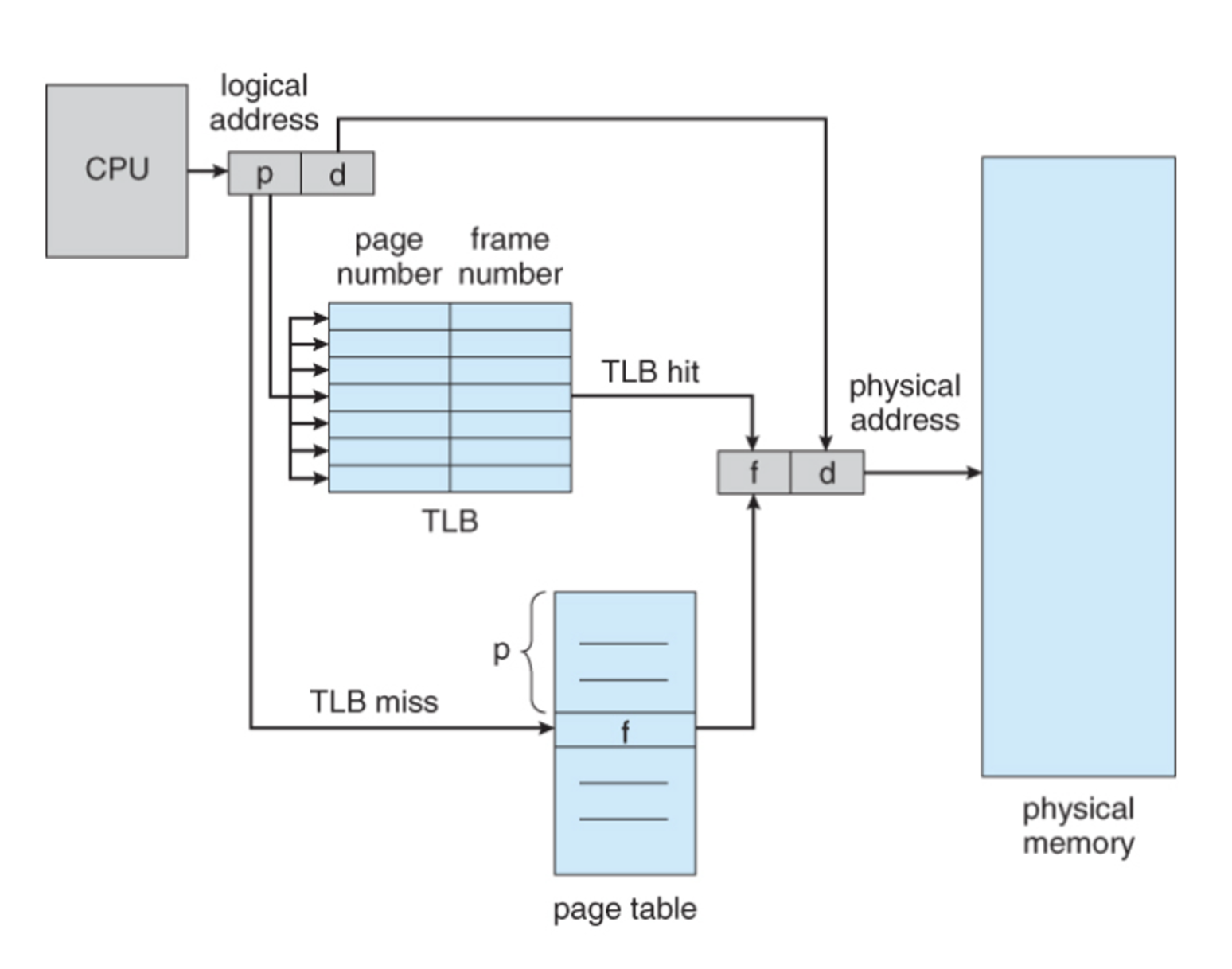
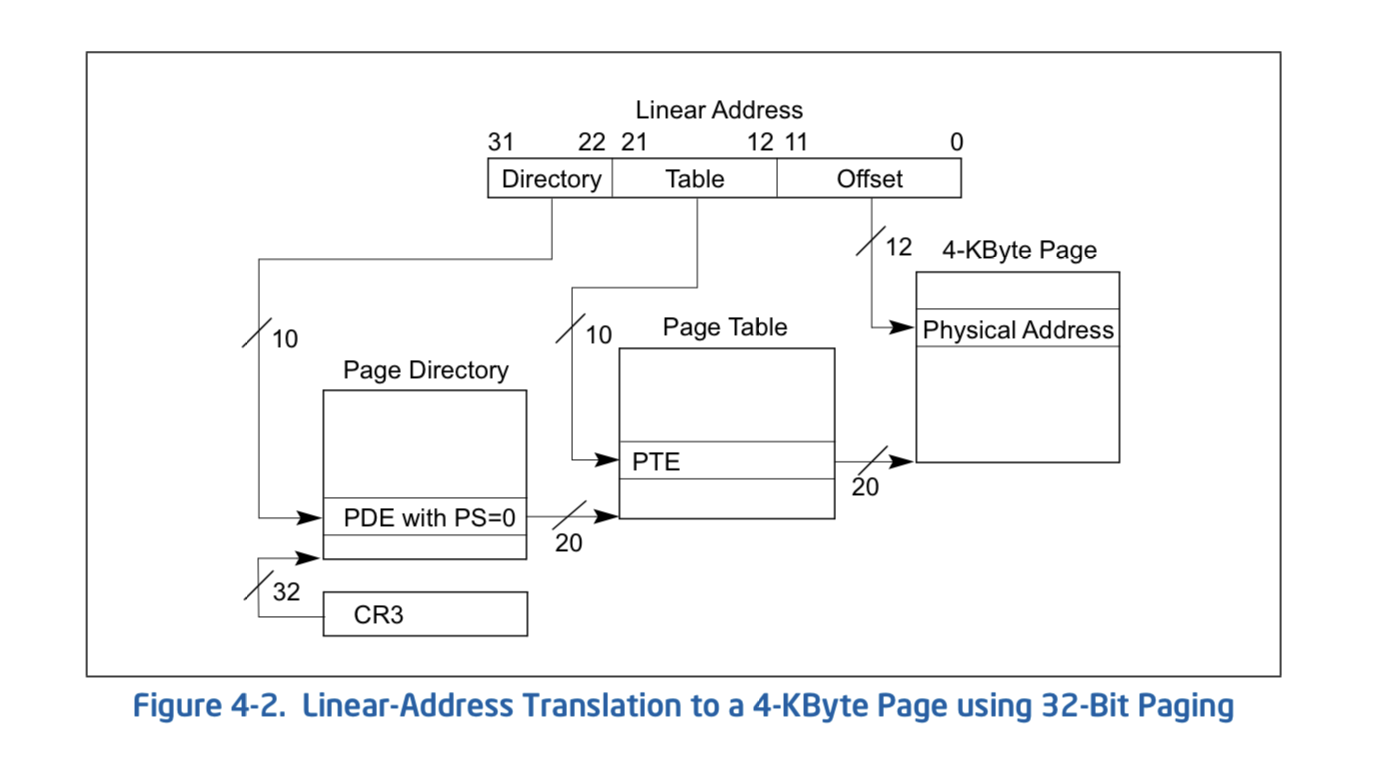
- 실제 page table는 page directory로 구현되어있어, 더 많은 단계를 거침
+-----+
| PGD | **Page Global Directory**
+-----+
|
| +-----+
+-->| P4D | **Page Level 4 Directory** (optional)
+-----+
|
| +-----+
+-->| PUD | **Page Upper Directory**
+-----+
|
| +-----+
+-->| PMD | **Page Middle Directory**
+-----+
|
| +-----+
+-->| PTE | **Page Table Entry**
+-----+
- 해당 page table들도 모두 메모리에 (page 단위로) 올라가있음
- 변환시에 최소 4번의 메모리 접근을 해야함
- 때문에 TLB에 physical memory를 저장해서 메모리 접근을 줄인다!
tlb cache 정책은 어떻게?
- 프로세스 context switching 시에, TLB를 통째로 flush 시켜야하지 않을까? (프로세스들의 실제 physical address는 다르기에)
- 최근 접근한 메모리 영역들을 남겨둘까? → Temporal locality
- 인접한 메모리 영역들을 남겨둘까? → Spatial locality
context switch flush overhead
- TLB entry에 PCID (process context ID)를 저장해서 구분함
Temporal Locality
- LRU 알고리즘을 통해서 오래된 entry를 추출
Spatial Locality
- 4kb 페이지 단위로 인접한 메모리 영역 가져옴
- 가상 메모리상 인접한 page들을 prefetch하기도 함
Adaptive hash index
왜 필요할까?
B tree index
일반적으로 Mysql InnoDB 기준으로 default로 pk로 Clustered index를 가짐
- B+ tree 기반 인덱스
- 기본적으로 index는 disk에 저장함
- read 시, O(logN) 으로 검색 가능
- lead node에 row(value)들이 정렬되어 있어,
range read에 유리함
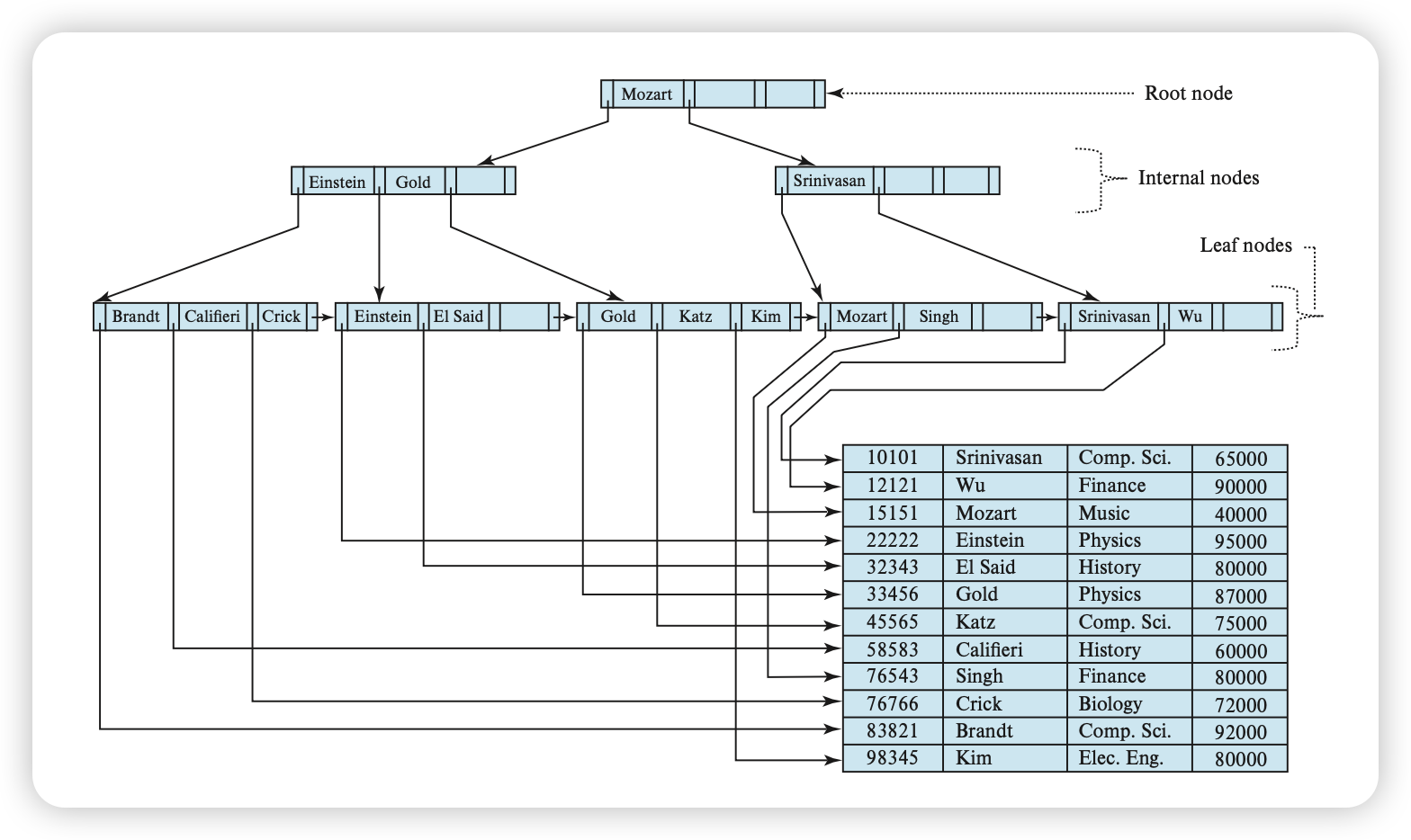 요건 사실 secondary index
요건 사실 secondary index
동일한 키를 매번 인덱스를 타야하나?
다만 B tree의 구조상, 자주 조회되는 특정 key들이 있다면 매번 B tree를 찾아가야 할까?
물론 자주 접근되는 노드들은 memory 상에 캐시되어(파일시스템 page cache) 디스크로부터 가져오는 번거로움은 덜겠지만 매번 O(logN) 탐색을 해야하는 문제가 있음
이를 위해 도입되는게 Adaptive hash index (key를 기준으로!)
The adaptive hash index enables
InnoDBto perform more like an in-memory database on systems with appropriate combinations of workload and sufficient memory for the buffer pool without sacrificing transactional features or reliability. The adaptive hash index is disabled by theinnodb_adaptive_hash_indexvariable, or turned on at server startup by--innodb-adaptive-hash-index.
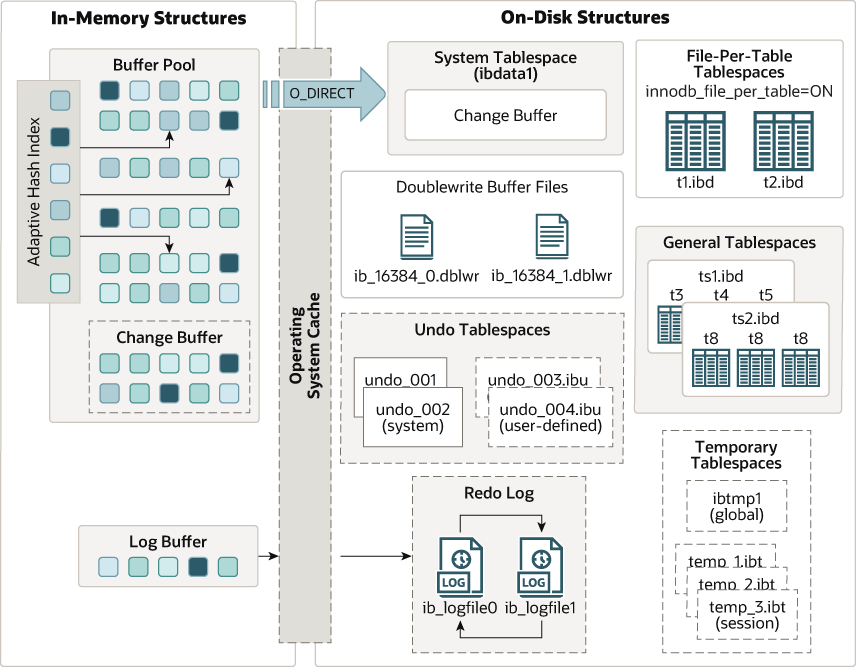
여담 (BE라면 알아야할 DB 상식)
ACID
A : 원자성
- transaction이 겹치면 안된다!
- 결과 commited or 시작전이여야한다
C : 정합성
- 데이터에 대한 일관성을 가져야한다 (balance 잔액) : 0이상이여야함
I : 격리성
- 트랙젝션끼리 얼마나 격리를 시킬꺼냐
- read uncommited (dirty read)
- read commited (non-repeatable read)
- repeatable read (phantom read) 10개 → 11개 : 이게 가장 많이써요 innoDB default
- serializable (table 자체 락을 잡아여) : 거의 안씀
MVCC(Multi version concurrency control)
D : 지속성
- 한번 저장된것은 persistent 저장해야한다 disk에 저장
- Doublewrite buffer
- undo Log
- Redo Log
1. update 쿼리 들어옴 row 하나
2. Undo log 작성 (snapshot을 떠서 롤백 용도로 사용)
3. lock을 잡아버려~ => 여기서 DB죽으면 어캐될까요?
4. 데이터 변경
5. unlock
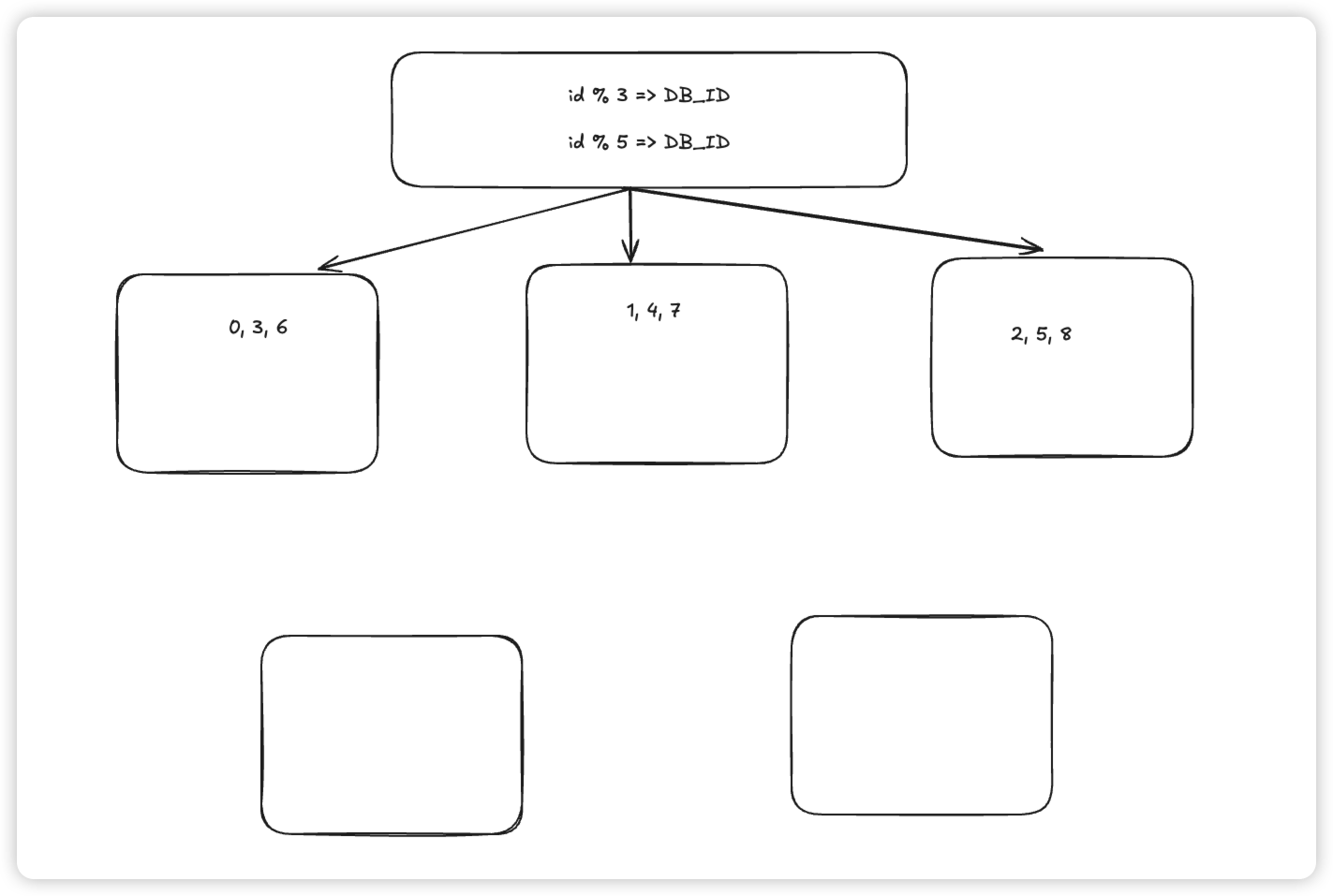
6. Redo Log 먼저 쓰고 -> disk fsync()partition key 파티션 키 정책
- 모듈러 기반 : id(pk) % 5
- 그럼 수평적 확장을 하면 어떤일이 발생할까
- 범위 기반 : 0~ 1000(db1) , 1001 ~ 2000 (db2)
다음 주차 예정
- REDIS
- CDN