Positional Embeddings
왜 필요할까?
The dog chased another dog → 위치 정보가 없다면, dog1와 dog2를 구별 불가능
code
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
model_id = "meta-llama/Llama-3.2-1B"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
text = "The dog chased another dog"
tokens = tok(text, return_tensors="pt")["input_ids"]
embeddings = model.embed_tokens(tokens) # 각 토큰에 대한 임베딩 batch 처리
hdim = embeddings.shape[-1] # metrics size 확인
# y = wx
# forward, backward 사용 가능
W_q = nn.Linear(hdim, hdim, bias=False) # query
W_k = nn.Linear(hdim, hdim, bias=False) # key
W_v = nn.Linear(hdim, hdim, bias=False) # value
mha = nn.MultiheadAttention(embed_dim=hdim, num_heads=4, batch_first=True)
# mha layer 모든 파라미터 초기화
with torch.no_grad():
for param in mha.parameters():
nn.init.normal_(param, std=0.1) # Initialize weights to be non-negligible
output, _ = mha(W_q(embeddings), W_k(embeddings), W_v(embeddings))
dog1_out = output[0, 2]
dog2_out = output[0, 5]
print(f"Dog output identical?: {torch.allclose(dog1_out, dog2_out, atol=1e-6)}") #True
- tokenizer : vocab를 만드는 모델
- word 단위로 짜르는 것보다 token으로 자르는게 좋음
- multi head attention을 통과한 dog를 같나 다른가 판별
- q,v,k
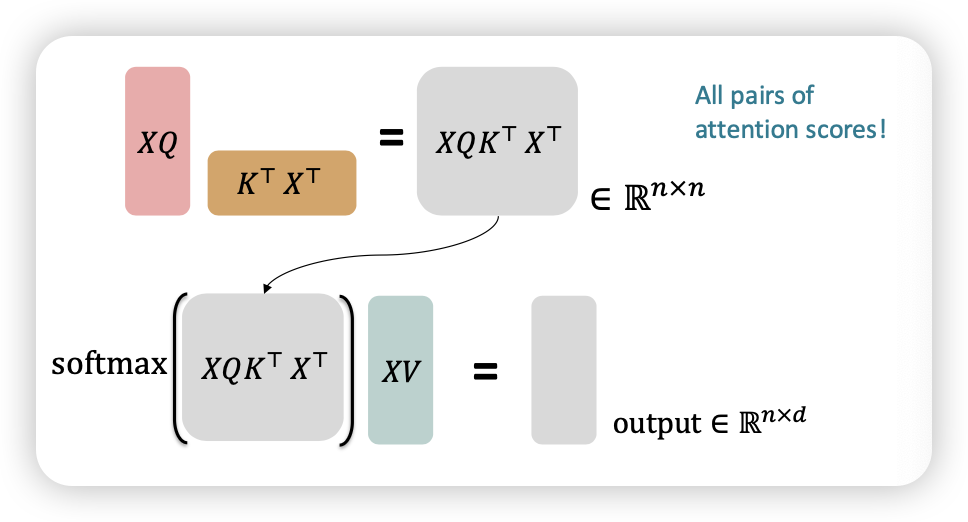
임베딩에 무슨 특징이 필요할까
- 각각의 unique 포지션들을 나타낼 수 있어야함
- 위치의 차이에 대한 정보 반영
- 긴 sequence에 대해 일반화 가능
- 랜덤되지 않은 과정을 통해 모델이 학습해야함
- 다양한 차원으로 확장 가능해야함
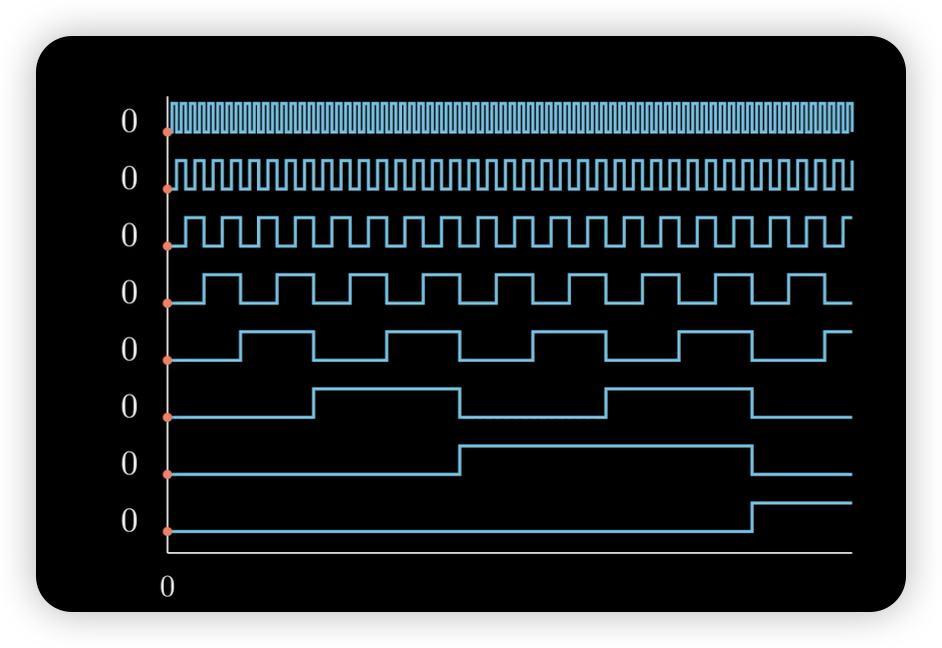
Integer Position Encoding
Binary Position Encoding
- 2진수처럼 1,0 만으로 표현 → range 압축
- sinusoids 와 비슷한 개념
- position embedding이 너무 날뜀
Sinusoidal Positional Encoding
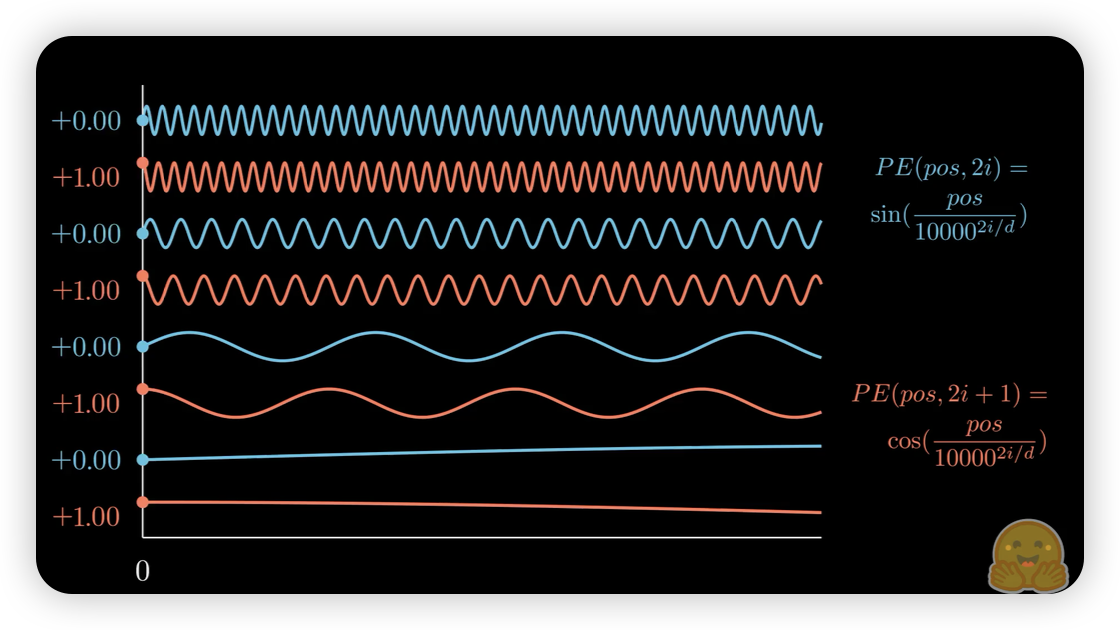
- relative position embedding을 만족하진 못함
RoPE
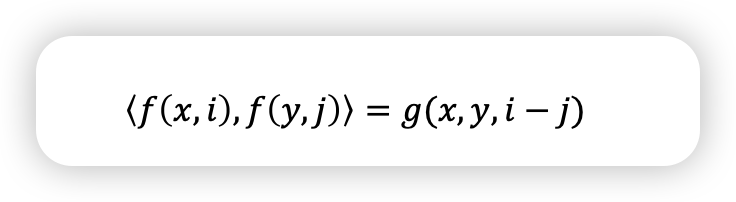
- f,y가 상대적인 position으로 표현할 수 있었음 좋겟네~
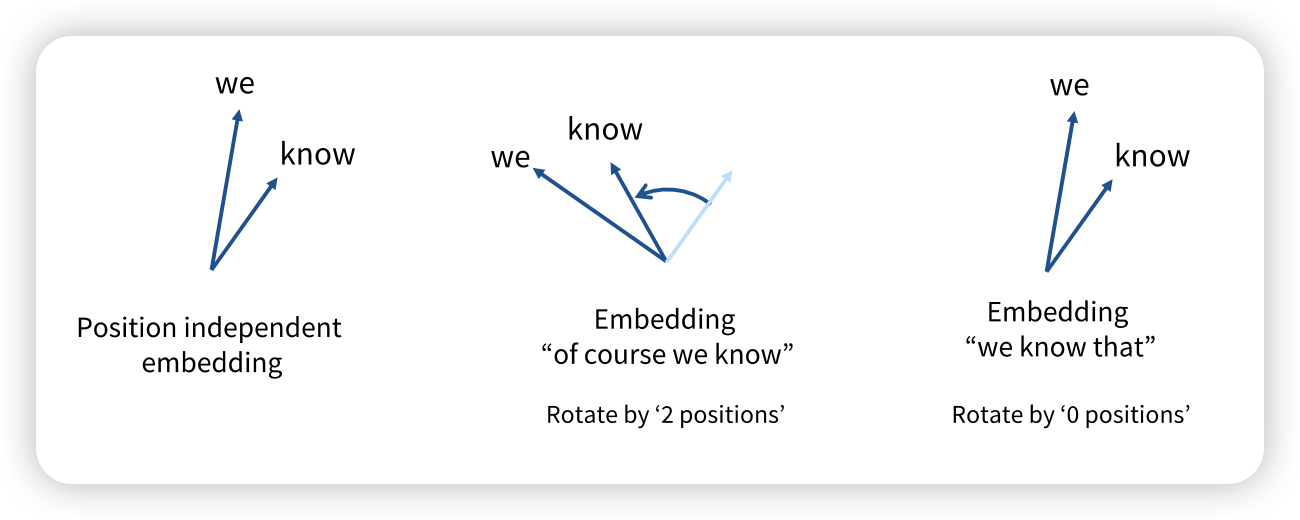
- inner product로 absolute position이 아닌 relative postion으로 표현하길 원함
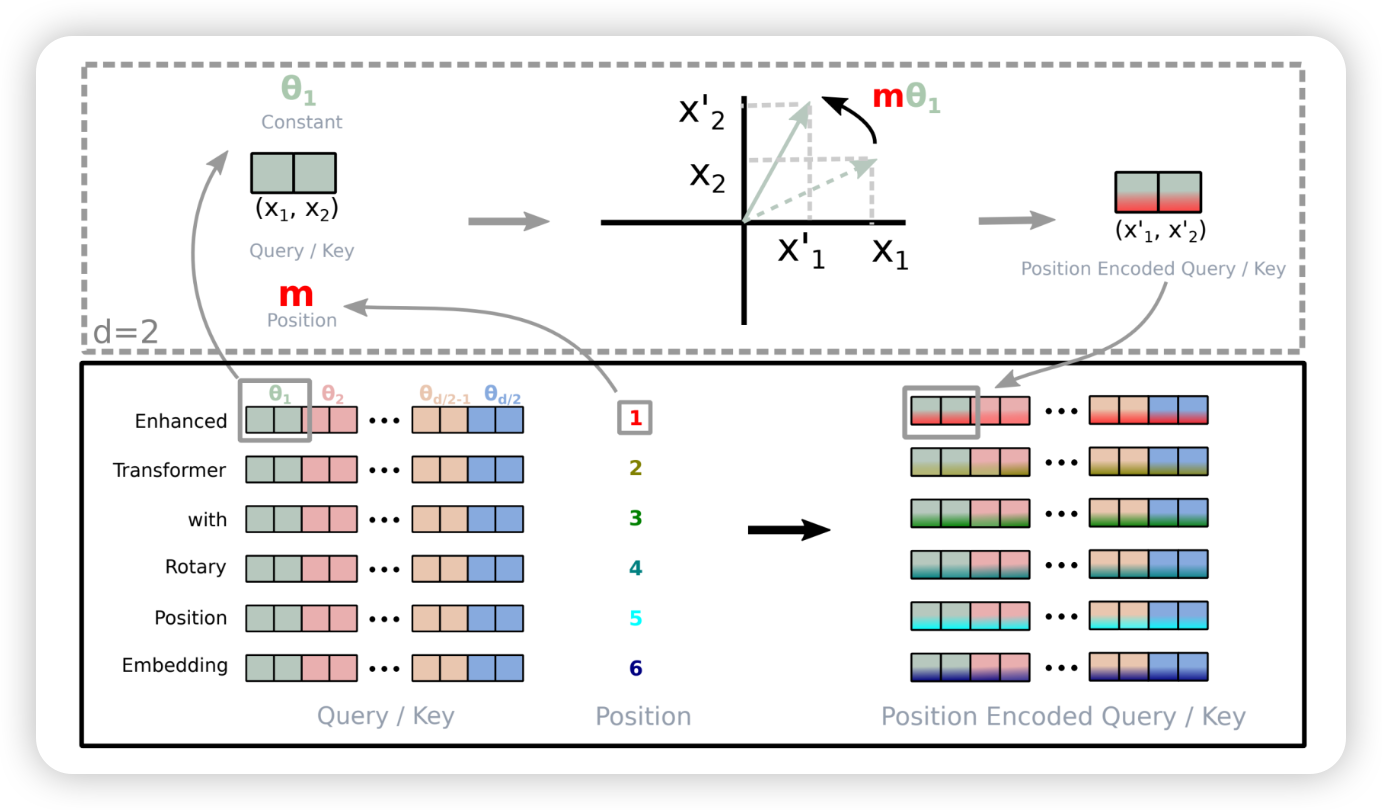
- position m을 통해 기존 qeury/key vector들을 rotation 시켜버림
- 현재 단계에서 가장 많이 사용
그래서 진짜 잘하나?
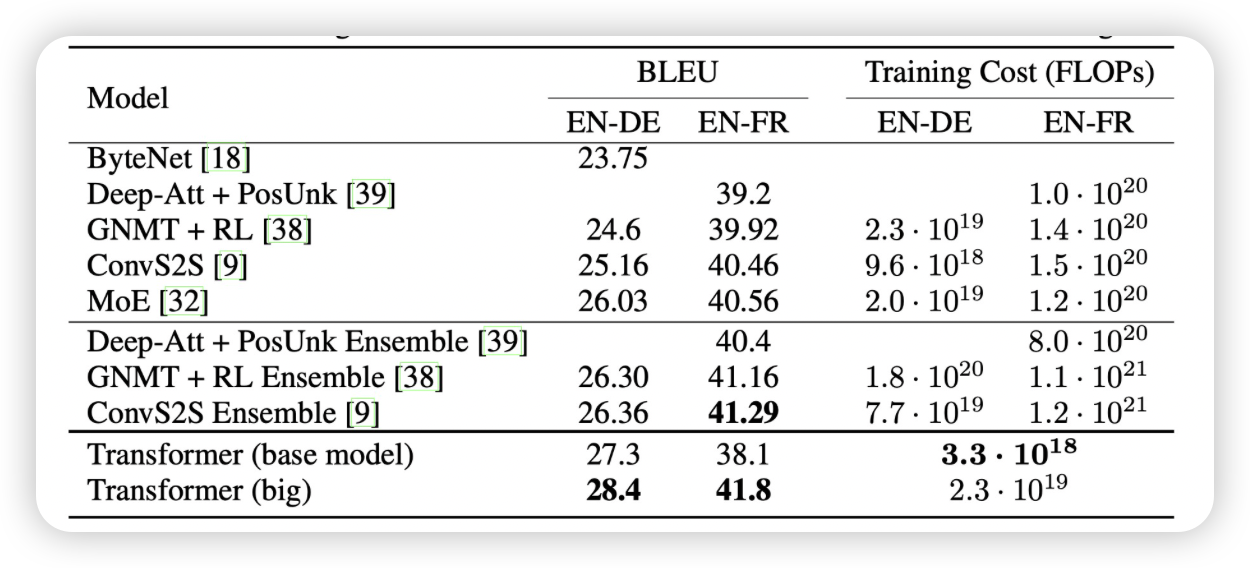
machine translation
BLEU : 번역된 reference랑 얼마나 비슷한가?
FLOPs : 연산량이 얼마나 많나?
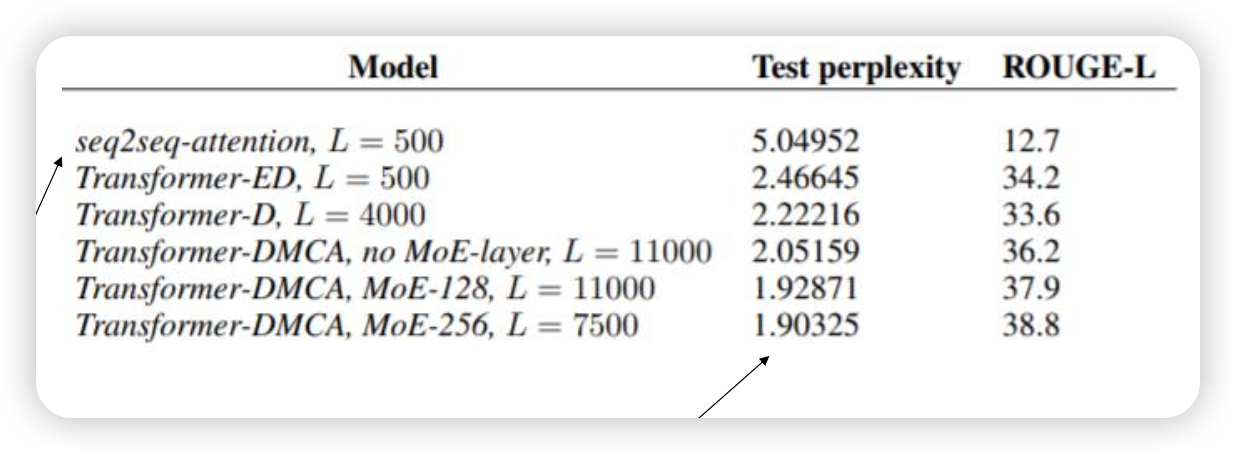
document generation
GLUE downstream task에서 얼마나 잘하는 지 종합적으로 판단
그럼 이게 짱짱이냐?
학습을 어떻게 안정화할건가
- 대부분 엔지니링 문제가 있음
pre vs post norm
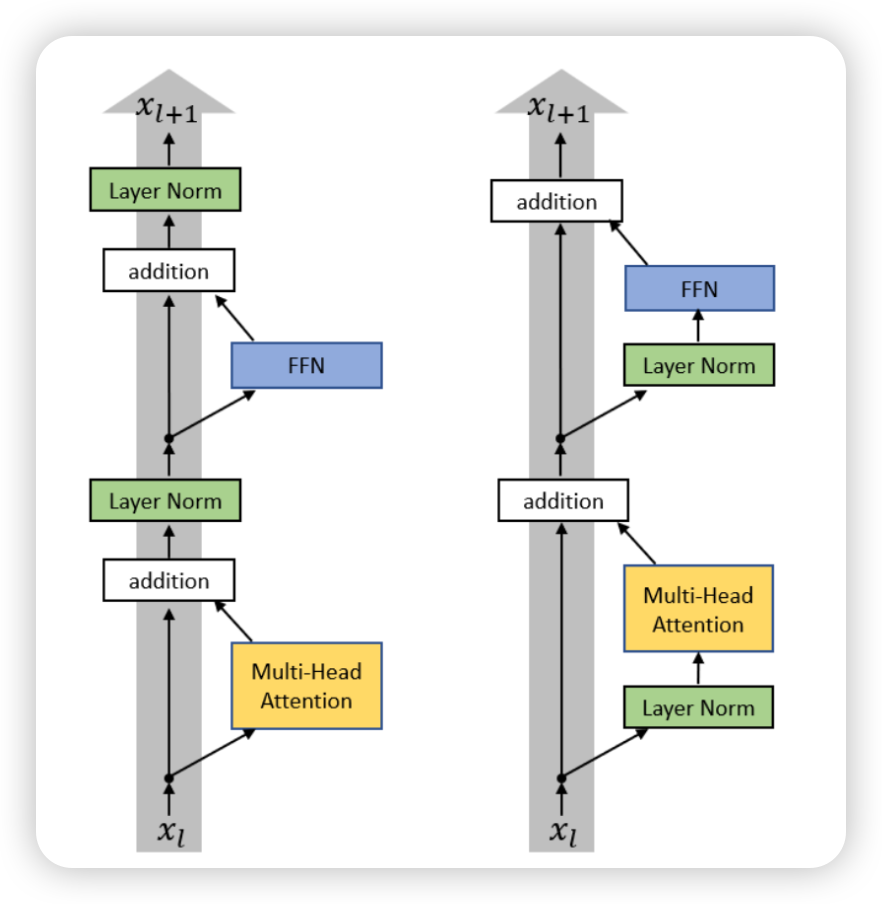
- multi attention 전에 normalization을 먼저 하는게 실험적으로 발견됨
Quadratic computation
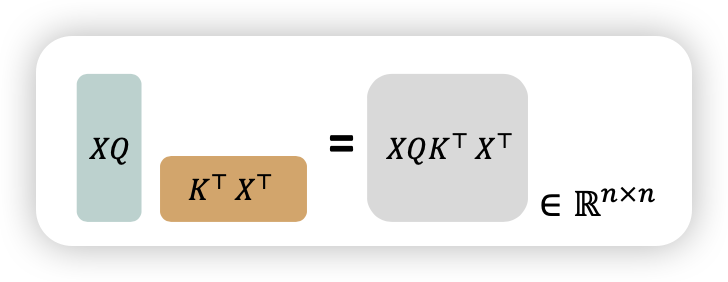
- 만큼의 연산량이 필요함
- 일반적인 LM은 d는 1000을 넘어감
- sequence가 길어지다 보면, 미친듯이 연산량이 늘어남
RNN으로 돌아가볼까..?
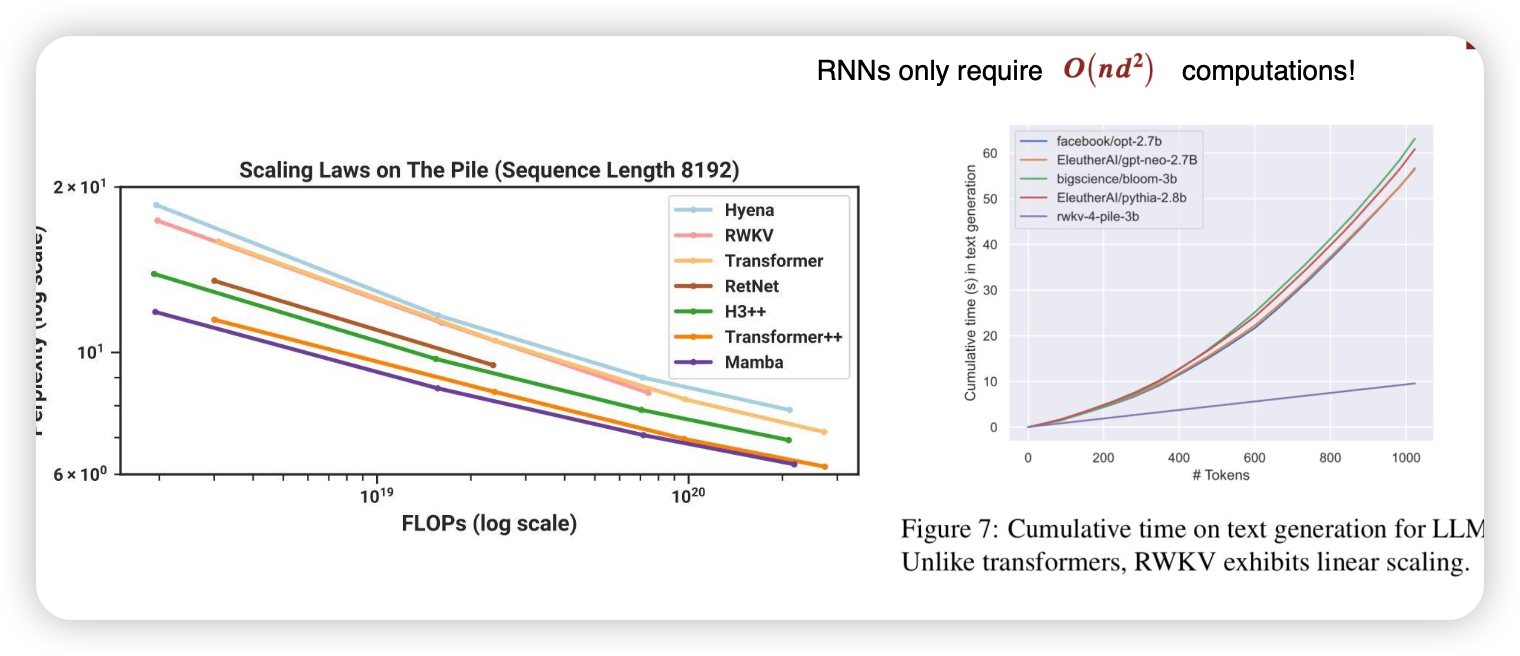
모델 아키텍처를 바꿔버릴까?
시스템 최적화를 해볼까? → (Flash attention)
현재 단계에서는 서로 싸우는중
Application
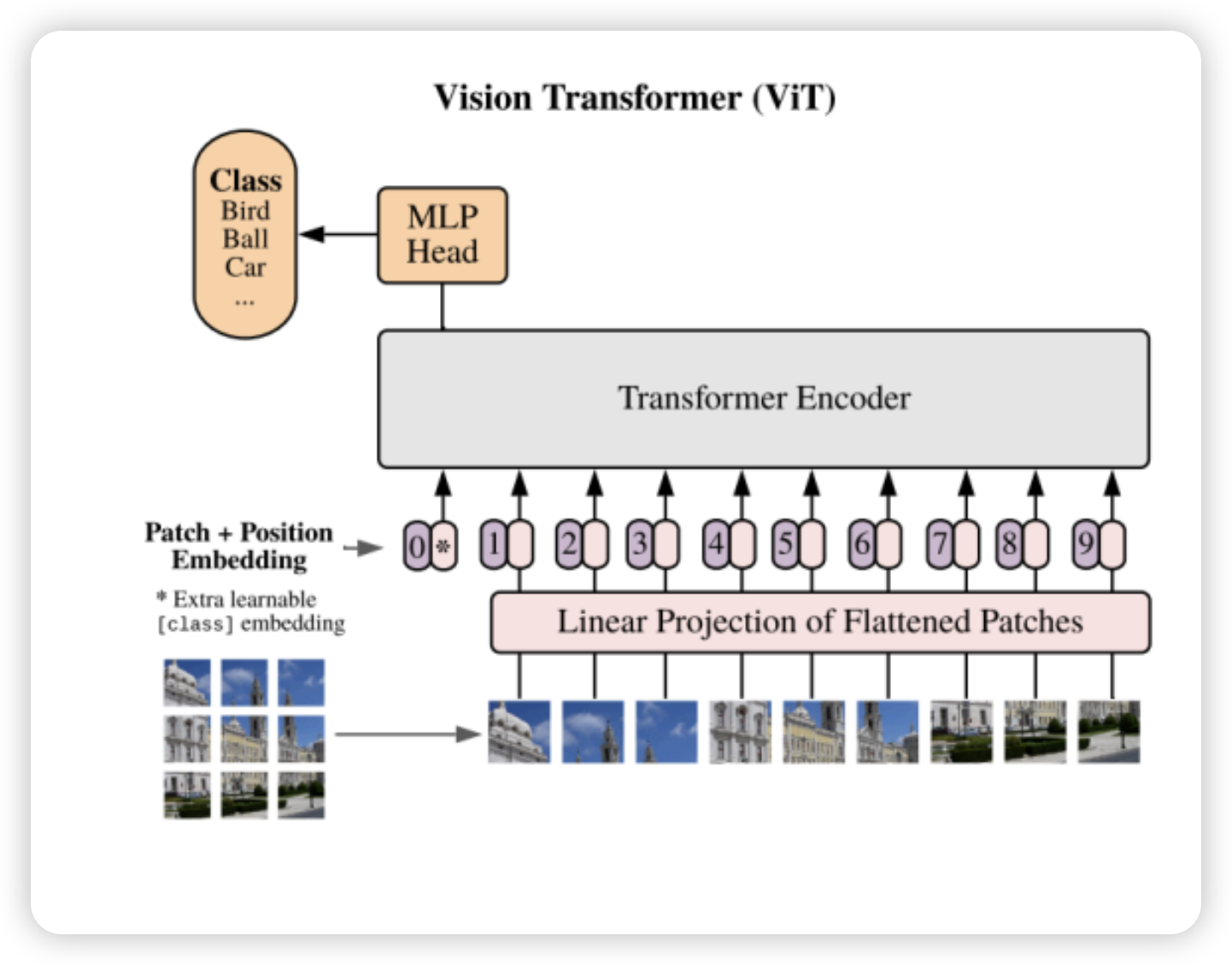
Vision
Wav
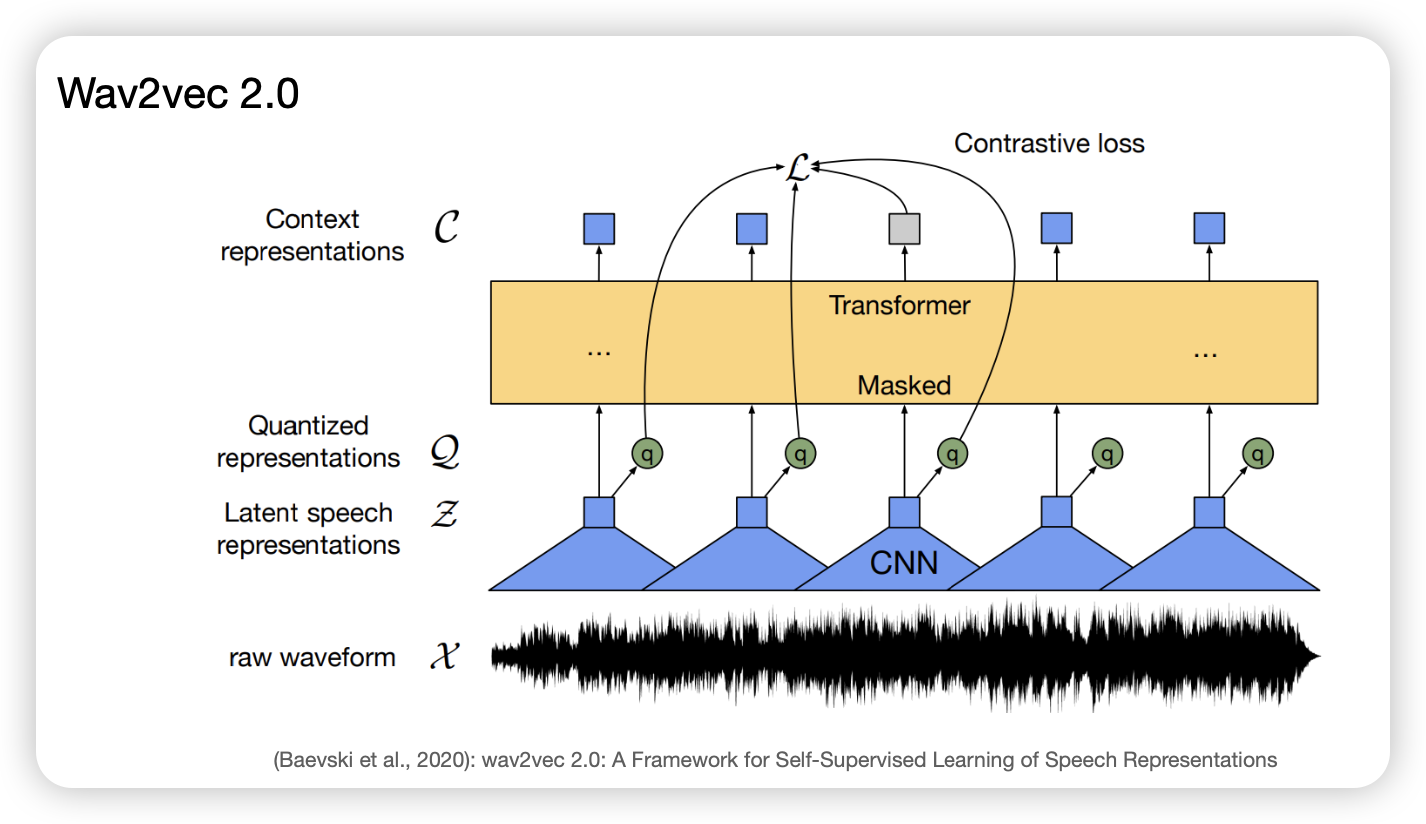
음성 데이터가 들어갔을 때,