챕터 목표
- bert 이후에 어떤 녀석들이 나왔나?
- chatgpt까지의 발전
- 그녀석들의 한계
Post Bert
RoBERTa
- BERT가 더욱 학습할 여지가 남아있다고 생각
- next sentence prediction loss를 제거함 →
- data size, batch size를 올릴수록 성능이 올라갔다..!

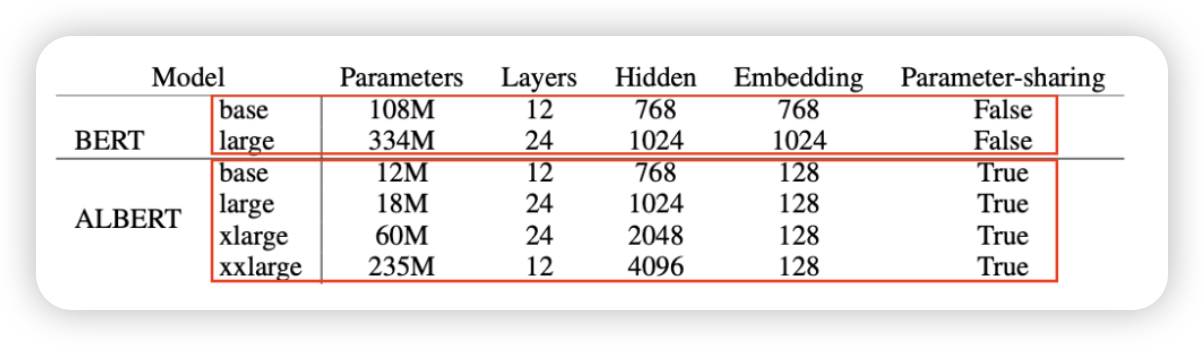
ALBERT
- 다른 레이어의 모델의 파라미터를 공유해볼까?
- 임베딩 사이즈를 줄여보자
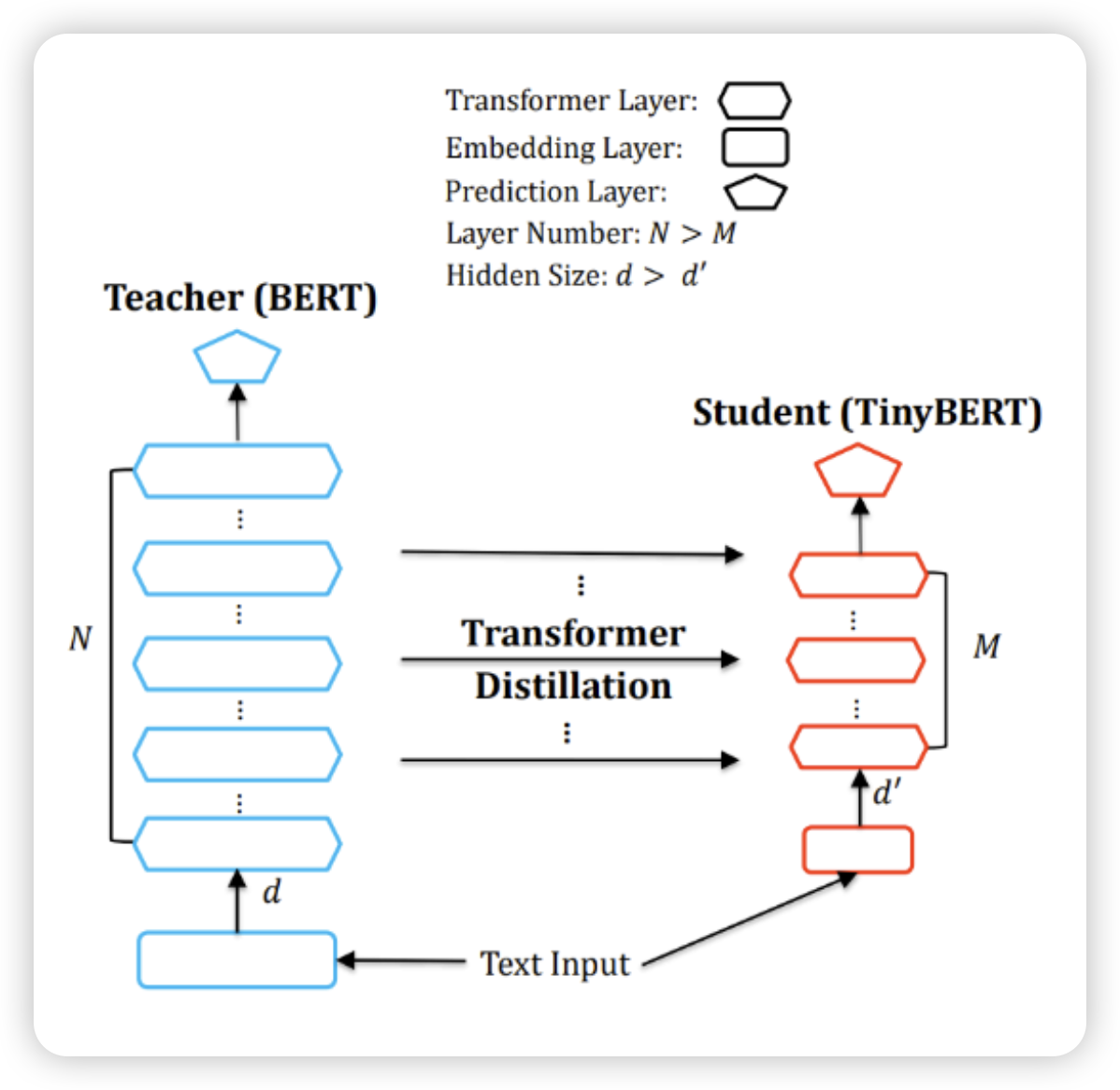
Distill, Tiny, Mobile BERT
- Distillation : teacher를 따라하게 만듬 → 모델을 압축한다
- BERT의 성능의 97퍼까지 따라옴
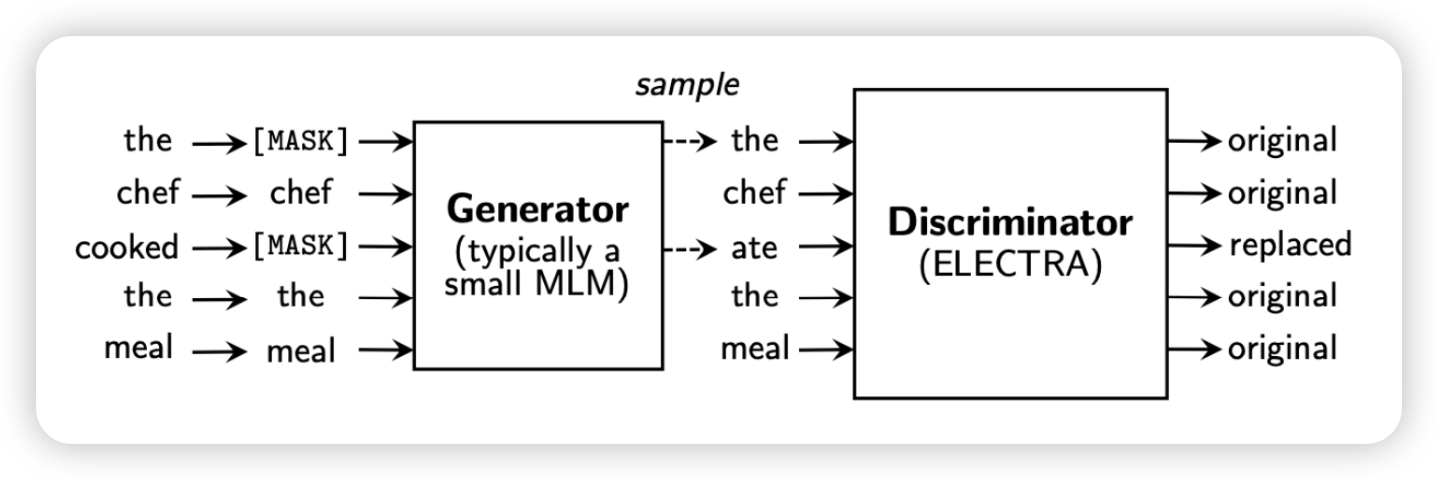
ELECTRA
- Generator
- 생성하는 모델 (BERT) → 마스크에 있는 단어를 생성
- discriminator를 더 잘 속이기 위해, 더욱 더 real 한 데이터를 생성
- Discriminator
- 생성한 데이터를 판단(진짠가..?)
- 단어들을 input으로 받아서 이게 masked되었는지 아닌지 판단
- downstream task 수행에 좋았다
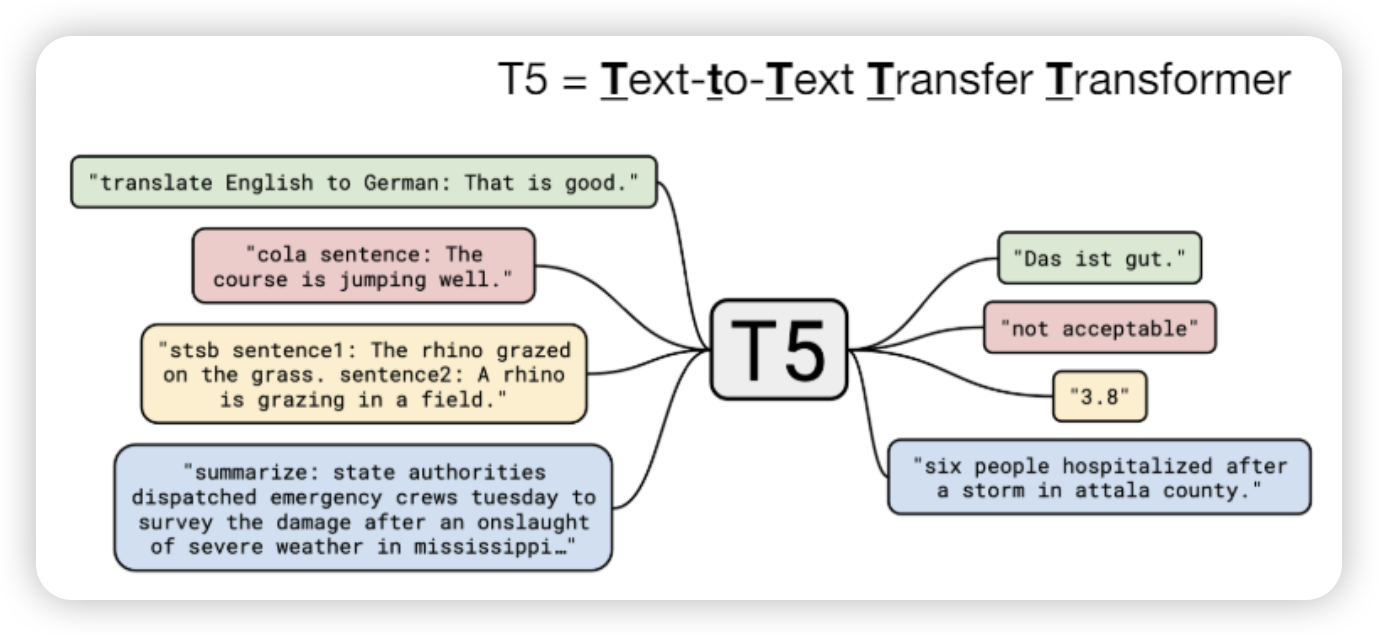
Text-to-text models
- BERT can’t be used to generate text
- 아예 text to text를 뽑아내는 모델을 만들자
T5 (Text to Text Transfer Transformer)
GPT3
GPT2 transformer decoder만 들고 와서 훈련시키자
- zero-shot : example을 아무것도 안주고 그냥 알아서 학습시킴
GPT3
이전에는 각 레이어를 따로따로 학습하면서 optimize를 했음
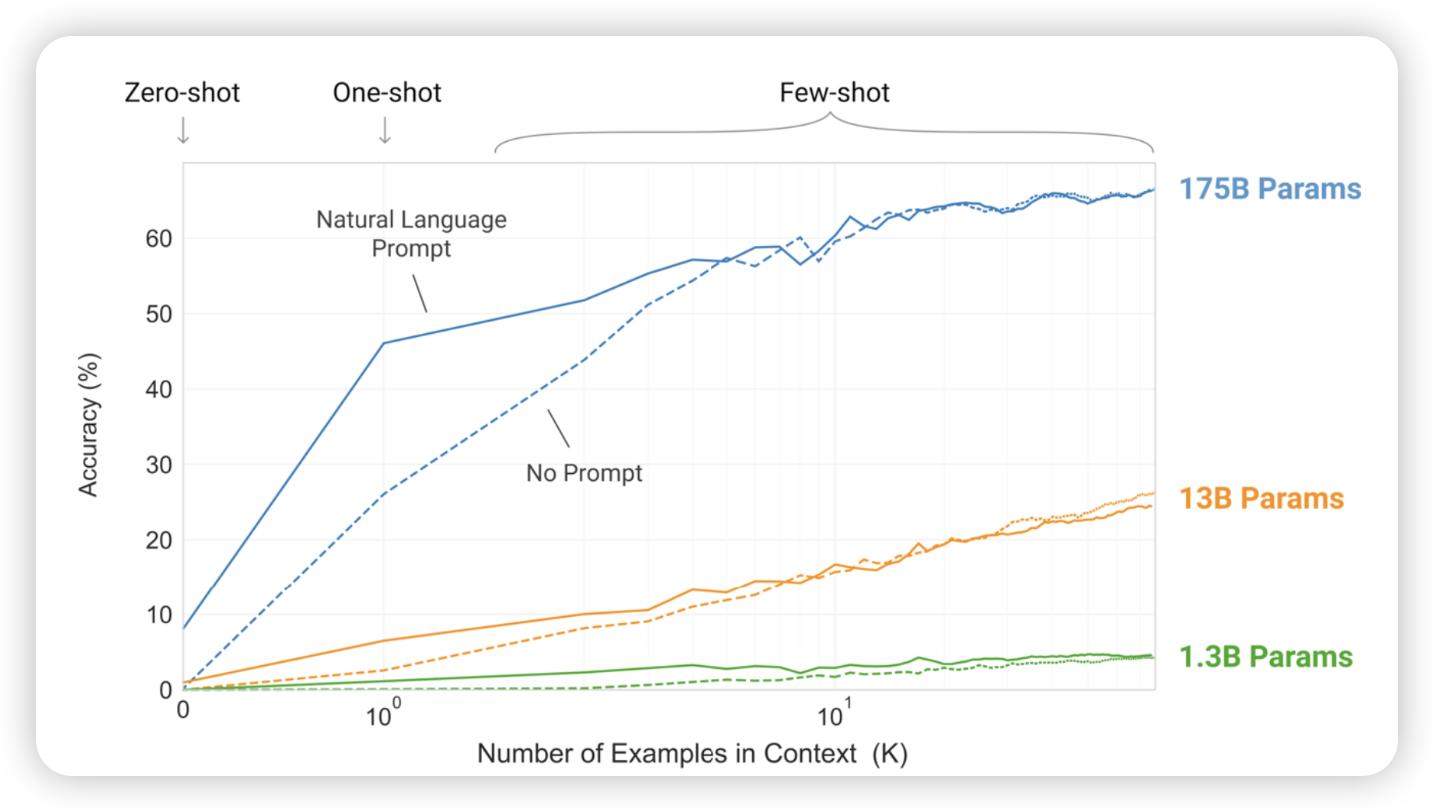
- few-shot learning
- fine tunning을 하지 않아도, input에 task, example을 넣기만 하면 문제를 해결함
- 새로운 task를 하려고 하면, 학습없이 해결할 수 있따
shot에 따른 정확도
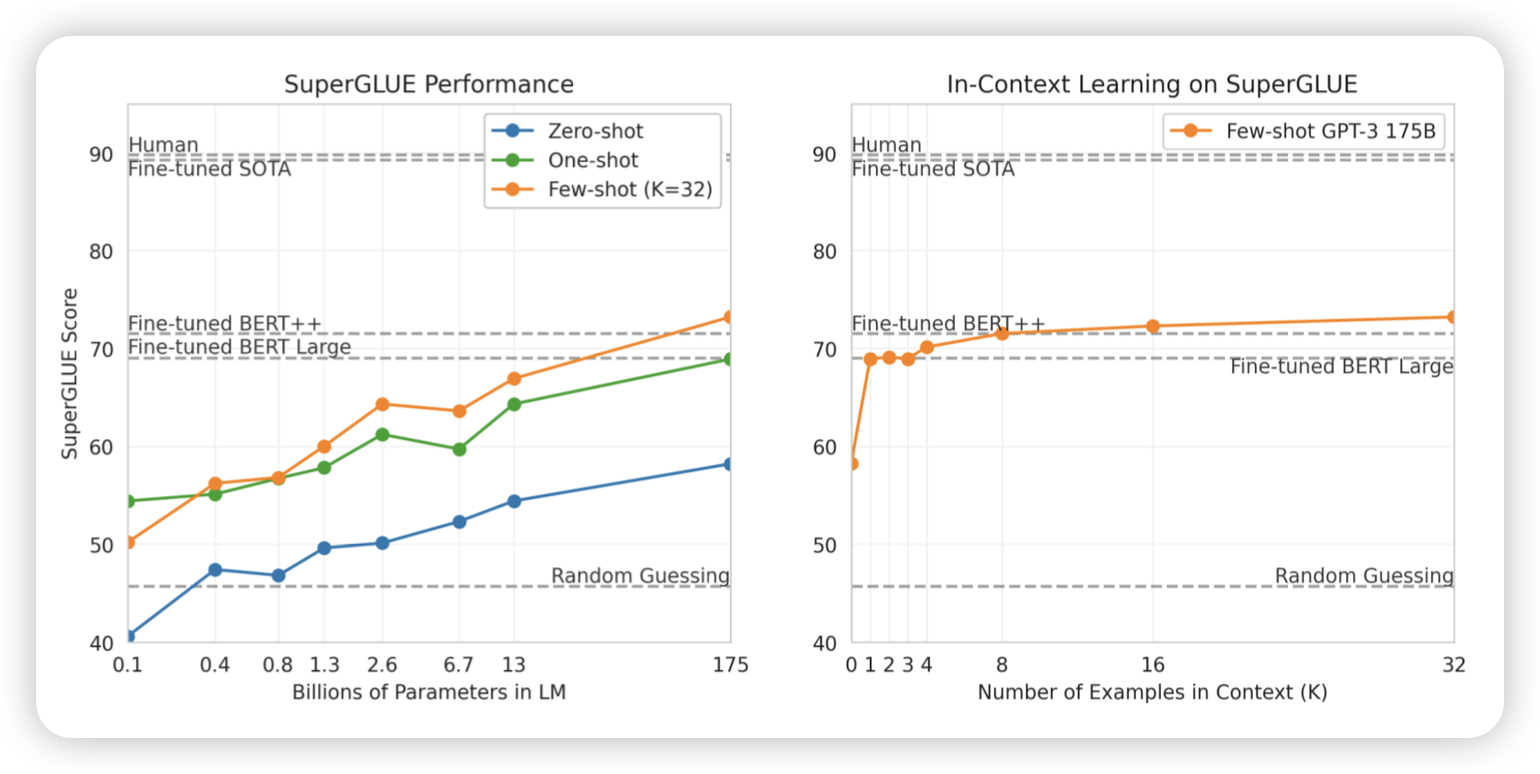
SuperGLUE 벤치마크
Chain-of-thought
- 답변을 내기 전에 답을 내리기전 reasoning 과정을 추가함
- 프롬프팅을 추가함으로 성능이 올라갔다!
- example을 추가하는게 아니라 단순히 instruction을 추가하자
Emergent properties CoT를 도입하고 나서, 특정 태스크에 따라 모델 사이즈가 영향을 미치기도 함
- 모델의 크기 (parameter size)
- 모델 학습에 필요한 연산량 (flops)
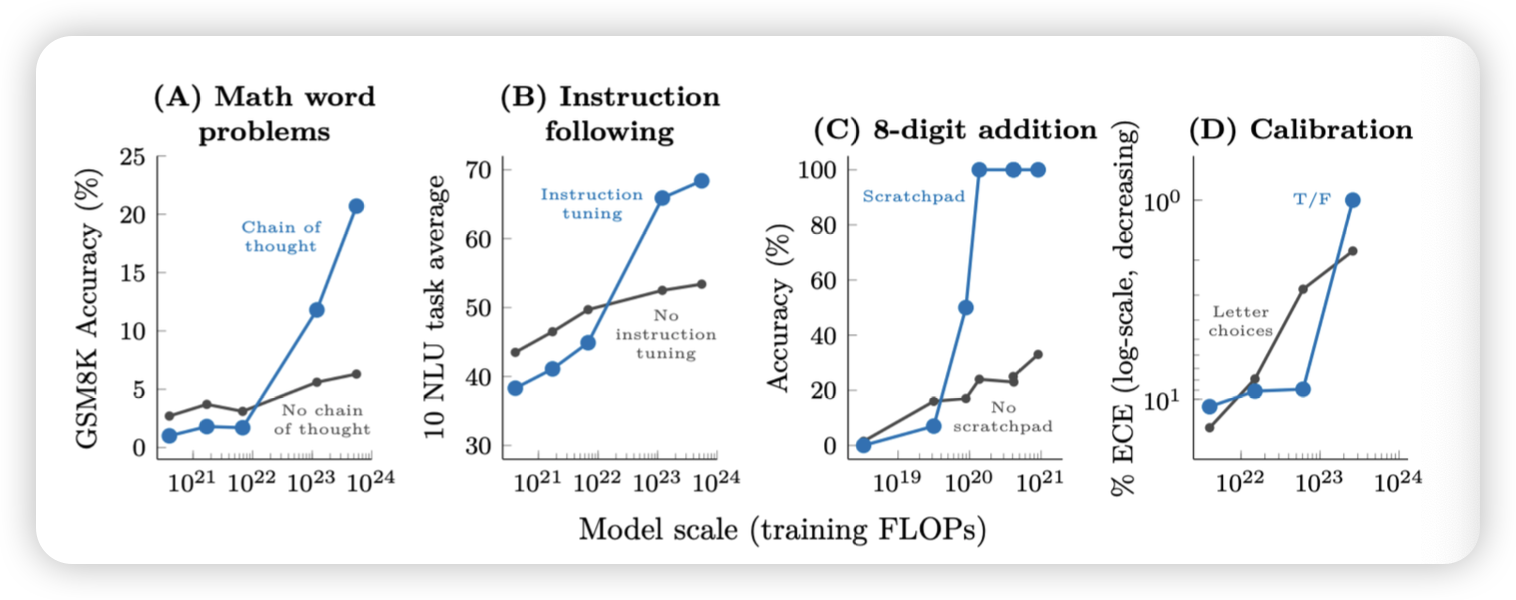
- 비판?
- evaluate metric이 binary여서 문제가 있었을 수도?
After GPT3
GPT3 이후 두 가지 방향
- codex initial
- instruct data
- qna, sumarize, generate 를 통해 학습
이후 두개를 합침
- 비율은 주인장 비법 secret
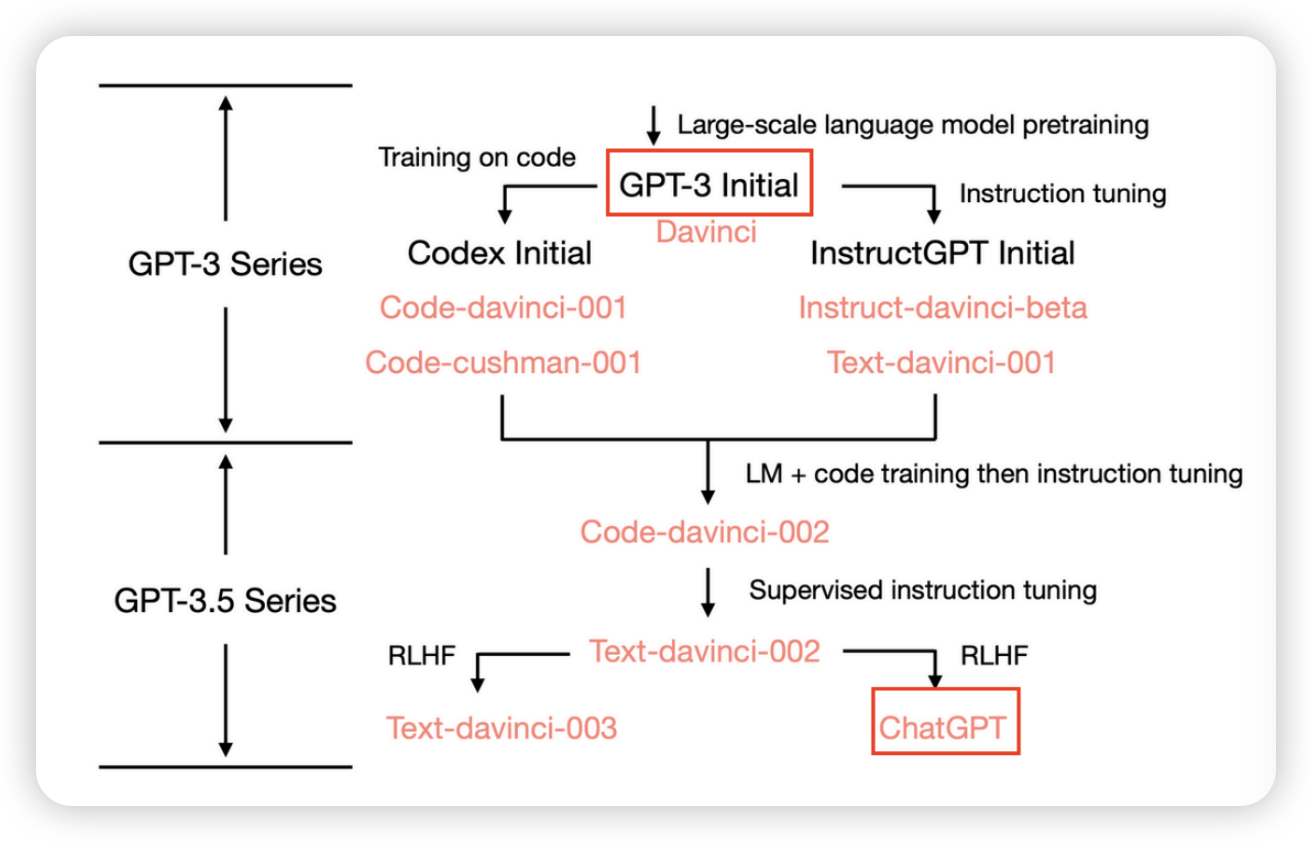
어떻게 만들었나
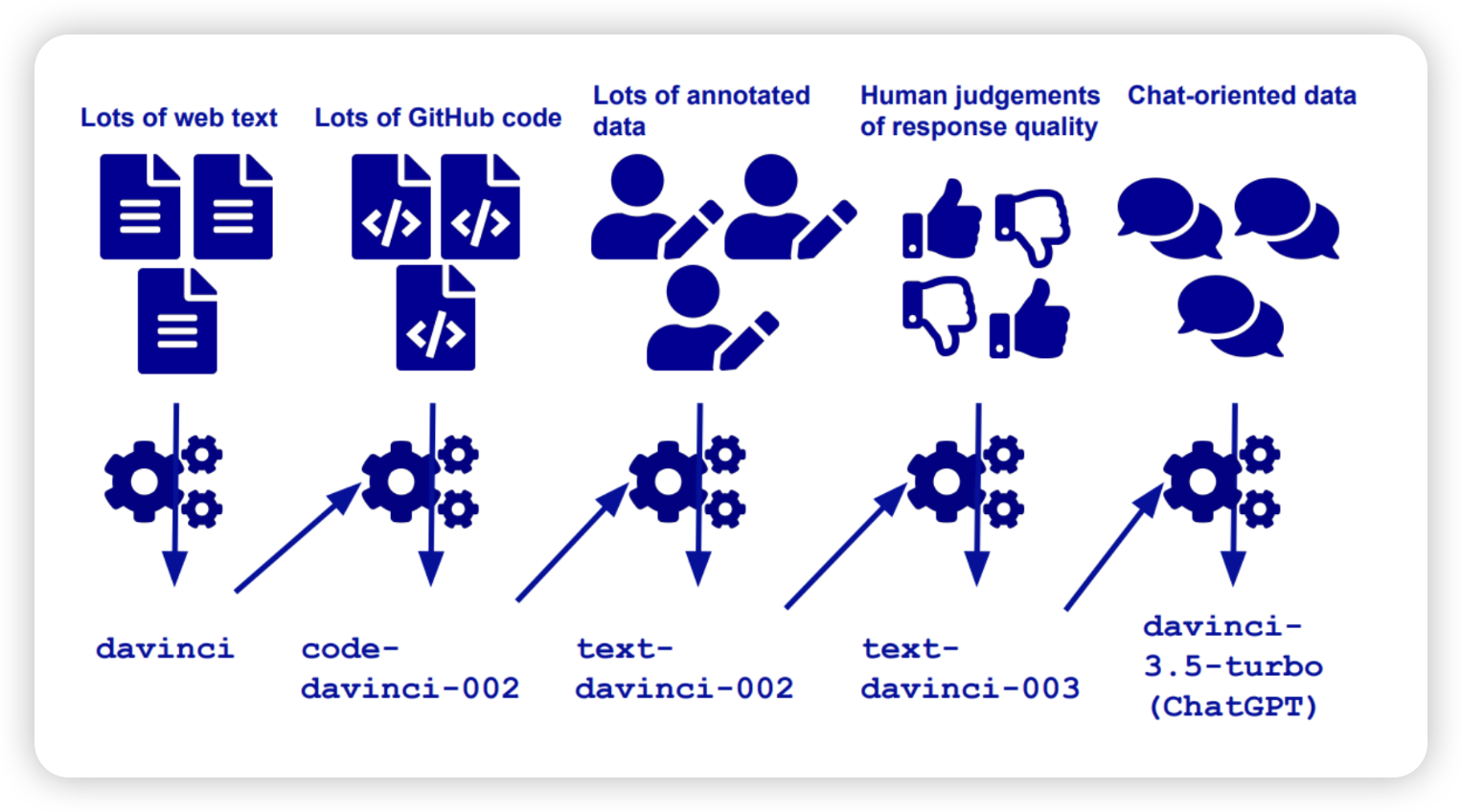
InstructGPT Supervised instruction tuning + RLHF (Reinforcement learning from human feedback)
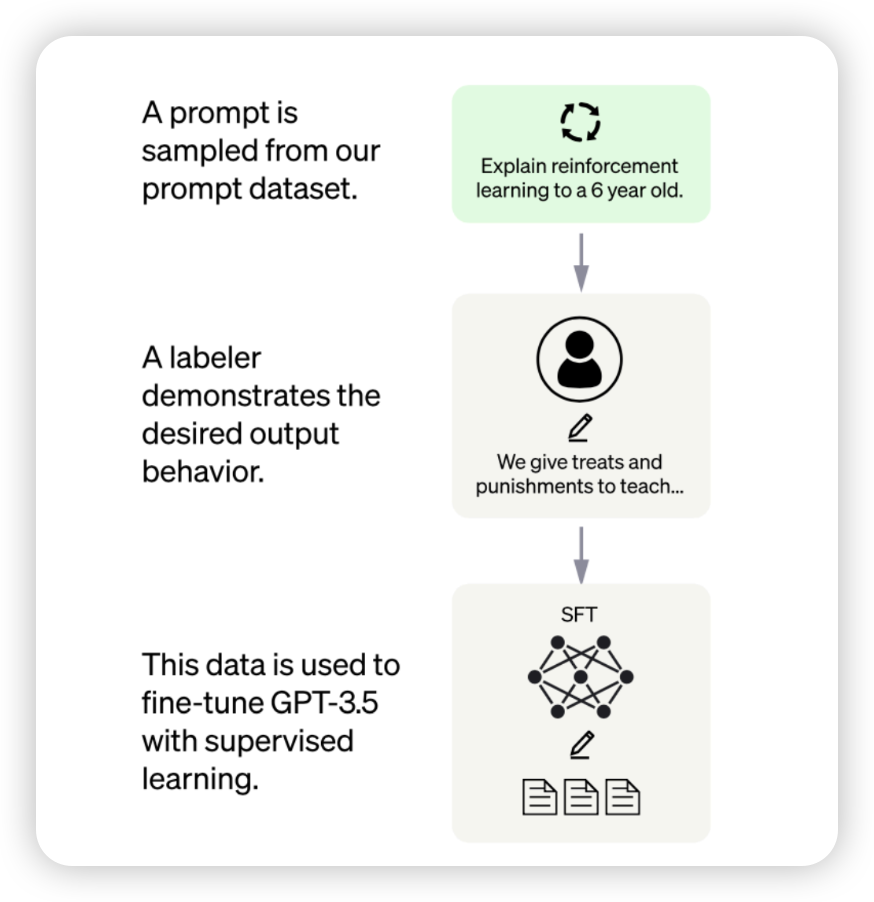
-
input, output을 매칭해서 supervised tunning을 진행함

-
데이터 annotation을 누가 하느냐에 따라 영향을 받기도 함
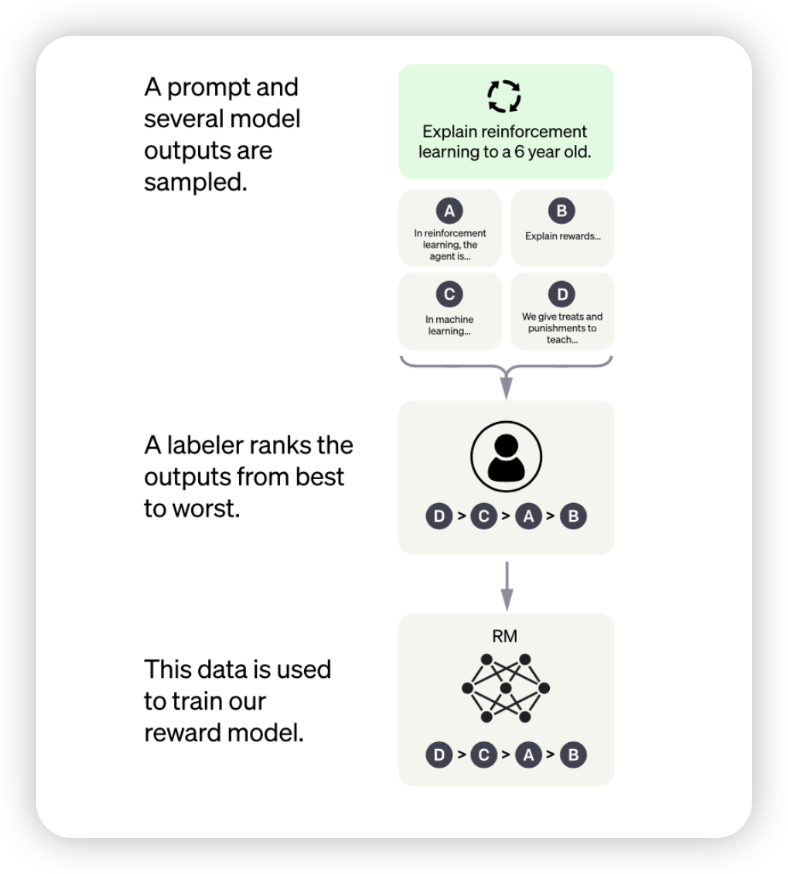
reward model
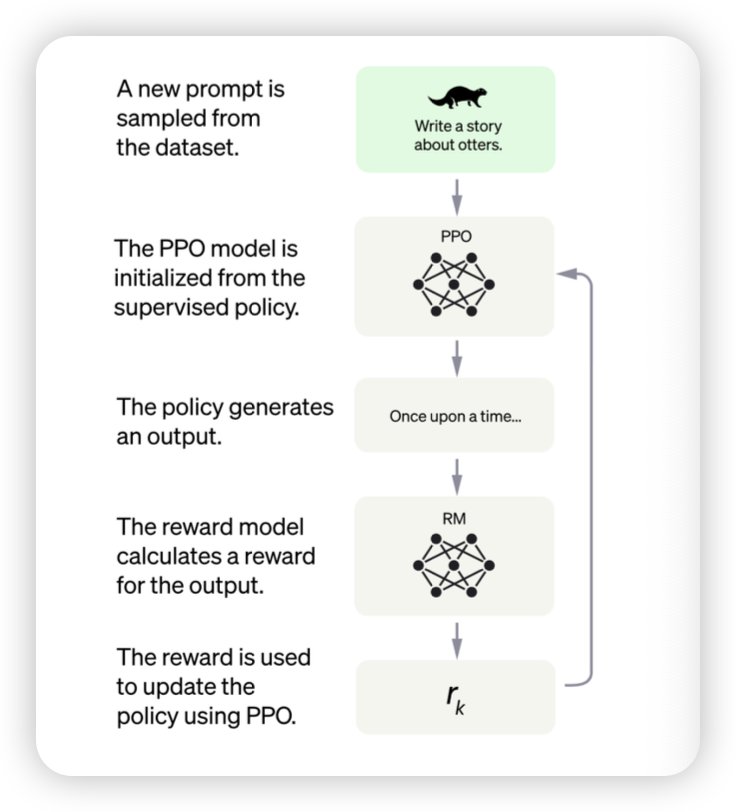
GPT4
- multi-modal
LLM Limitations
- 최신 정보를 어떻게 반영할까?
- 할루시네이션
- LLM security
- 학습데이터의 개인정보, 민감한 데이터를 어떻게 걸러낼까
중간 어캐 준비할까요?
- 다 서술형이다 wow wow