Attention
use direct connection to the encoder to focus on a particular part of the source sequence
mean-pooling

- hidden activation을 어떻게 하나로 요약해서 vector로 만들 것인가?
weighted averaging (Attention)
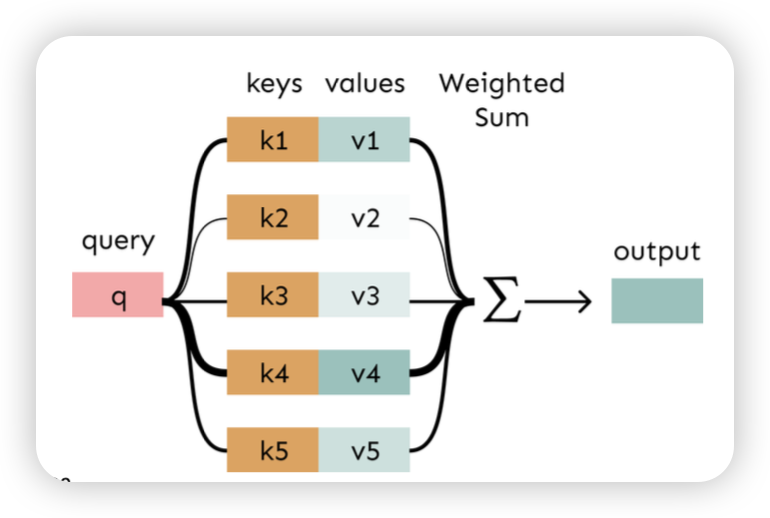
- mean pooling이 단순 평균이라면, weighted sum을 통해 vector를 만듬
lookup table
Sequence-to-sequence with attention
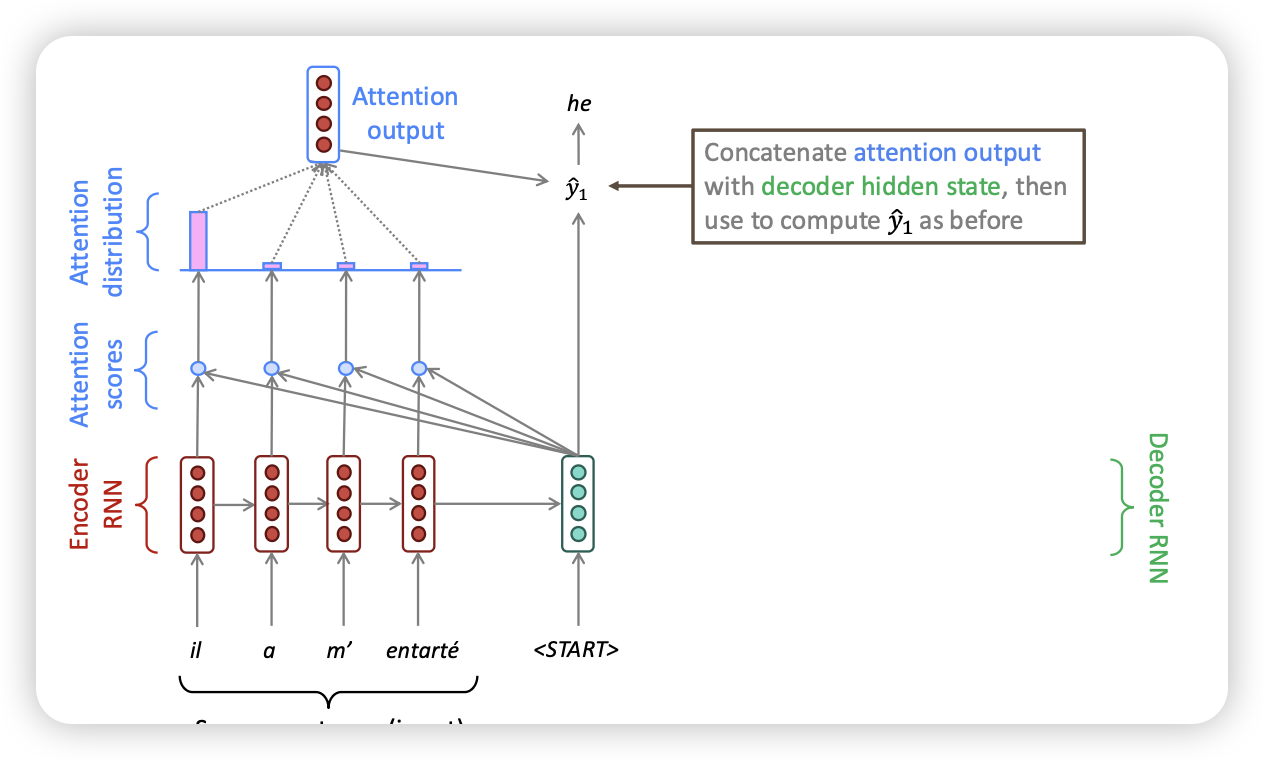
- Start point와 각 input을 dot product하여 attention score을 구함
- 해당 output을 softmax 때려서 attention distribution을 구함
- attention distribution을 weight으로 sum을 통해 attention output을 구함
- decoder hidden state와 attention output을 concat해서 decoder output 출력
개쩌넴
- attention을 추가해도 각 layer를 병렬적으로 처리할 수 있다! (RNN과 동일)
- 사람같이 직관적인 모델
- vanishing gradient 문제 해결
- bottleneck 문제 해결 (각 layer마다 replace 가능한 단어 찍기)
- 해석하기 좋은 형태 (attention map)
- MT 말고도 음성인식에서도 활용 가능
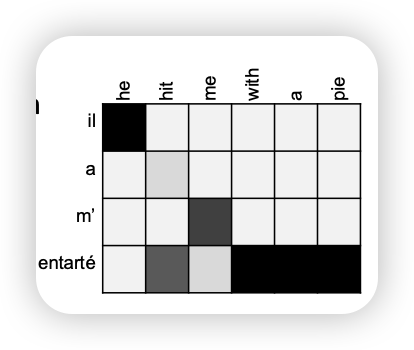
- MT 말고도 음성인식에서도 활용 가능
이슈
- softmax는 계산량이 많아서 이걸 decoder하나씩하면 오래걸리는데..?
- 어떻게하면 attention map을 picky하게 만들 수 있을까?
수식
정리
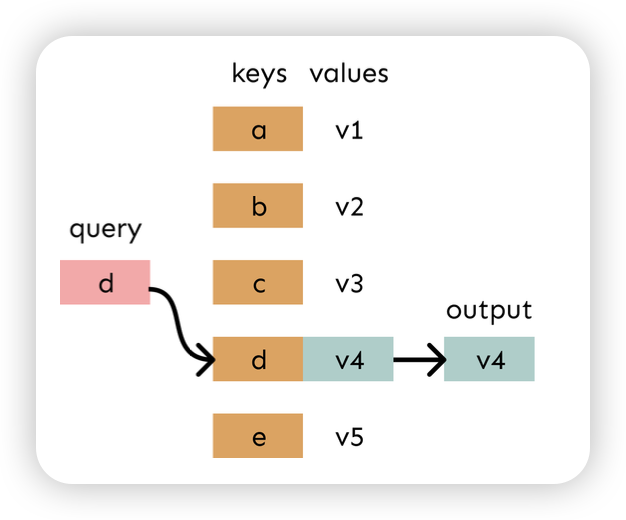
- Query, Key 구조를 가지고 weighted sum을 한다!
- Seq2Seq 말고도 다양한 Task도 가능
- Weighted sum은 사실상 selective summary(memory) 라고 볼 수있음
- attention output은