문장의 문법 구조에 대한 것
- 품사, 문장 형식?
특정 언어에 종속적임! 영어 != 한국어
Constituency
- 문장을 어떤 구조로 쪼갤 것인가?
- context-free grammars (CFGs)
- words → phrases → bigger phrases
Dependency structure
- 단어 사이의 의존관계를 확인
Look in the large crate in the kitchen by the door
Look in 의 target : the large crate large crate 의 describe : in the kitchen by the door
이런식으로 각
왜 문장 구조를 분석해야할까?
- 사람은 자연스럽게 문장을 쪼개서 Constituency와 Dependency를 파악함
- Model이 이러한 구조를
- sequence를 token으로 쪼개기 위해서?
그런데 문제는 없을까?
Prepositional phrase attachment ambiguity
- 같은 단어여도 문맥에 따라 ambiguity를 가질 수 있음
PP attachment ambiguities multiply
- attach를 어떻게 할지, 애매하게 생성될 수 있는 조합들이 늘어남
- Catalan numbers:
Coordination scope ambiguity (Shuttle veteran and longtime NASA executive) Fred Gregory appointed to board
(Shuttle veteran) and (longtime NASA executive Fred Gregory) appointed to board
Doctor: (No Heart), (cogintive issues)
Doctor: No (Heart, cogintive) issues
- Coordination에 따라 달라짐
Verb Phrase (VP) attachment ambiguity
Dependency paths
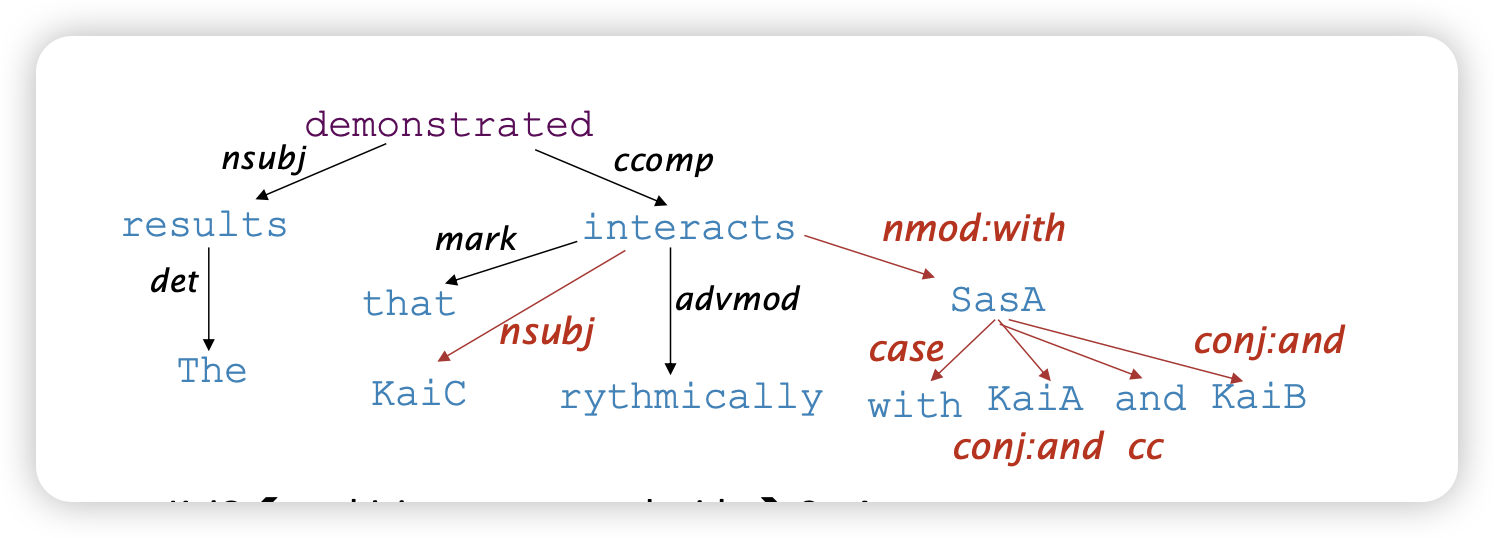
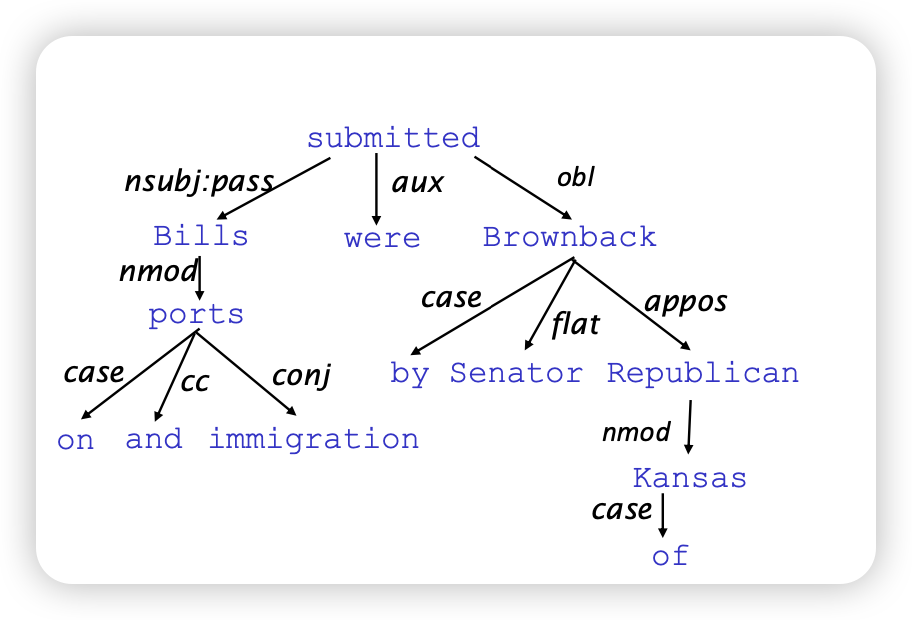
- 단어들 사이의 관계로 이어져있는지 명시함
- cyclic하지 않음 (트리 구조)
annotated data & Universal Dependencies treebanks
- 실제 parse tree를 만들기 위한 data는 직접 만들어놓음..
- NLP 시스템을 평가하는데도 사용함
Preferences
- Bilexical affinities : 관계는 유사함을 의미한다
- Dependency distance : 가까이에 있는 단어들이 관계가 있음
- Intervening material : 문장을 넘어서까지 관계가 거의 없음
- Valency of heads:
Dependency Parsing Task
- non-projective (dependency가 cross하지 않음 but language에 따라 다름)
- Only one word is a dependent of ROOT
- no cycle
어캐 구현함? DP부터 알고리즘으로 해결하다가 Transition-based parsing을 거처 neural network로 해결하자!
Greedy transition-based parsing
- greedy 방법으로 파싱함
- shift, reduce left-arc, reduce right-arc 중 하나를 선택함
- stack, buffer를 통해 현재 상태를 저장함
Arc-standard transition-based parser
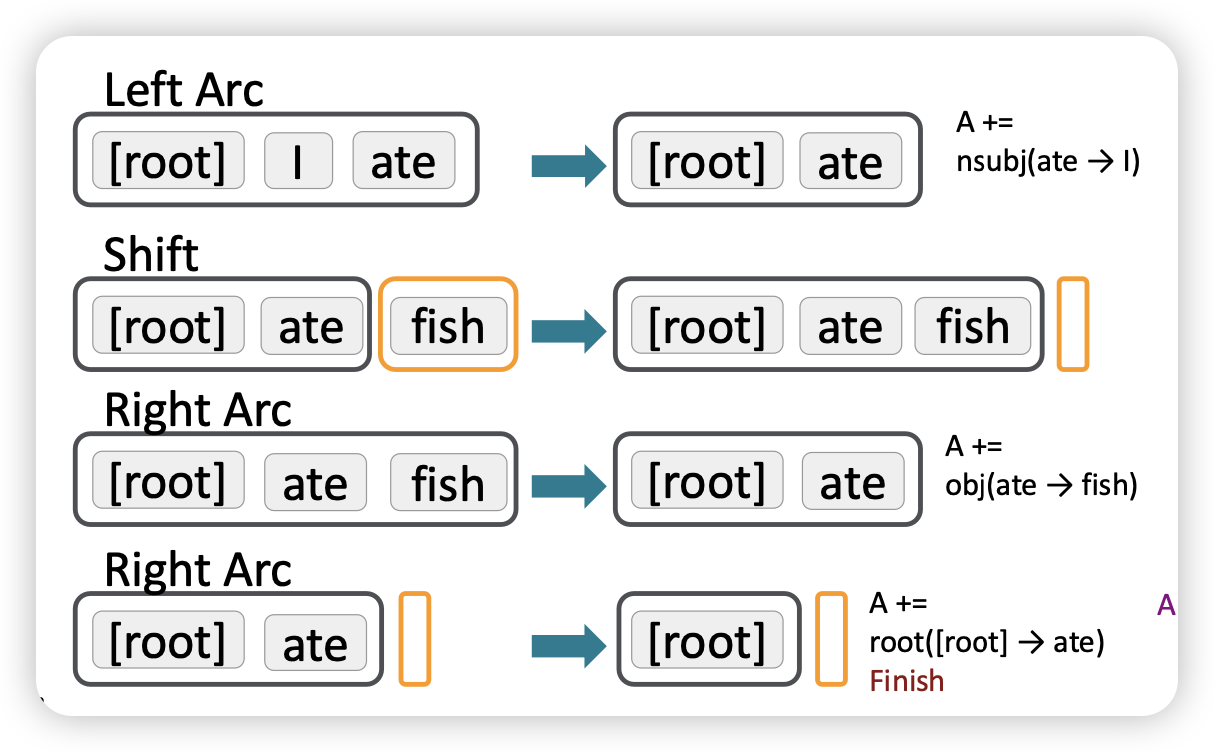
MaltParser
Stack, Buffer의 feature를 input으로 넣어 neural net으로 해결하자?
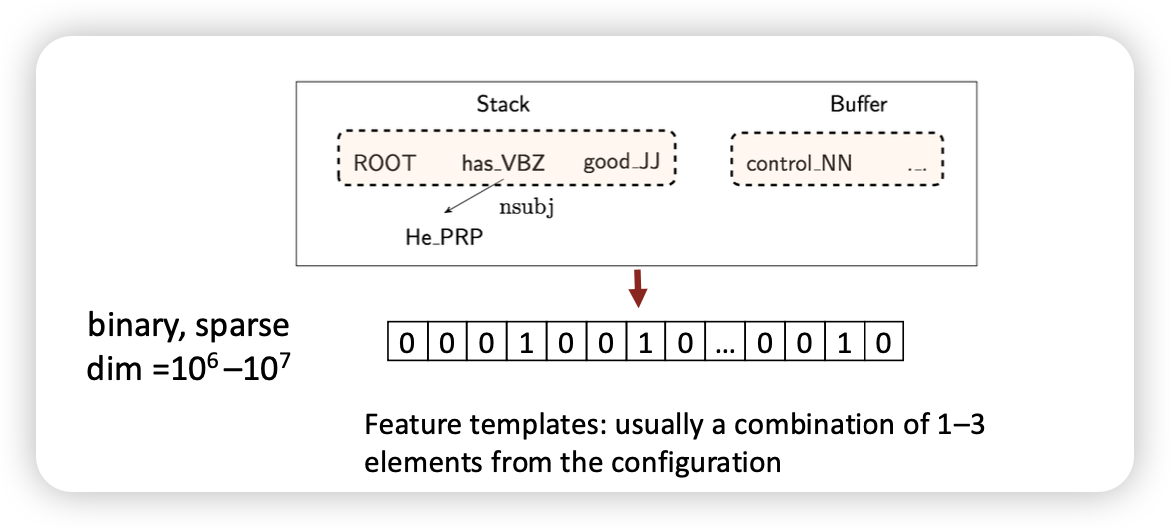
- one-hot encoding을 진행해서 feature로 넣음
Evalutation
A neural dependency parser
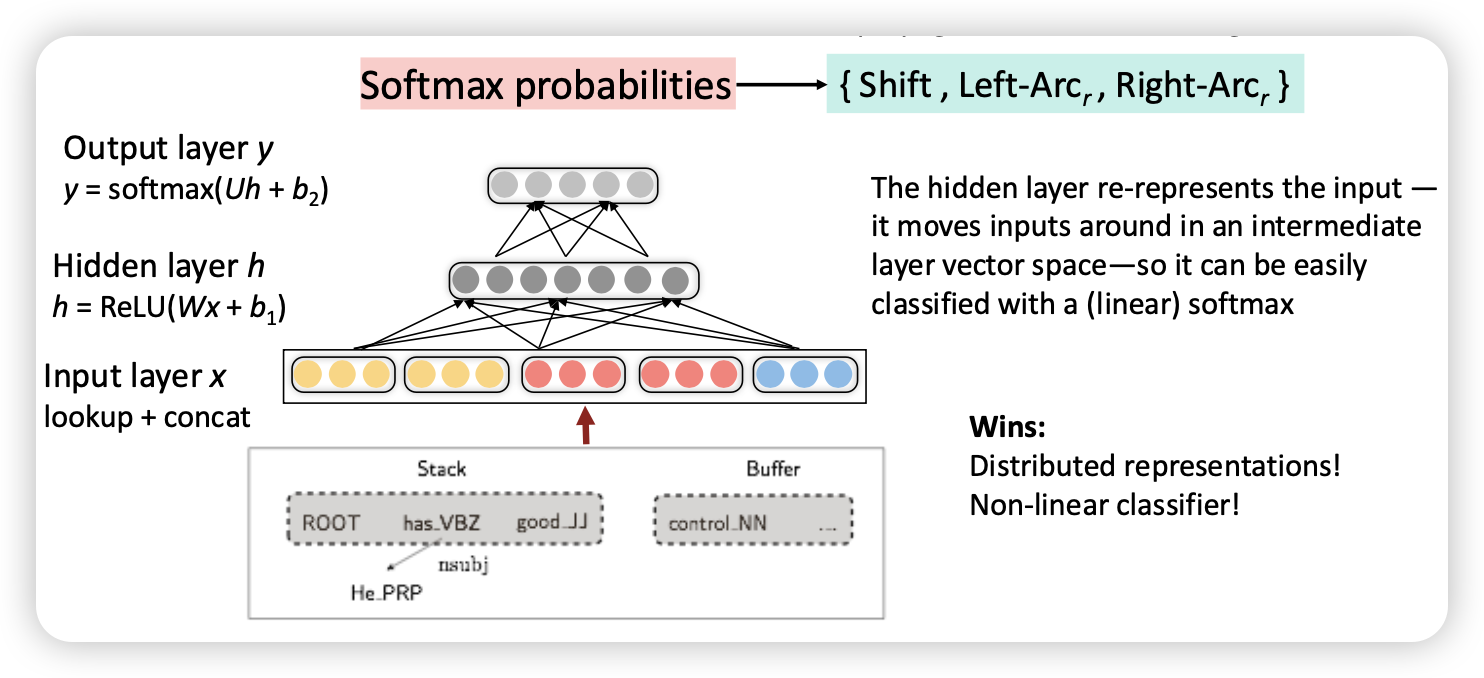
왜 잘됐을까?
- Distributed Representations
- soft-max classifier
- sparse해
SyntaxNet
- 지금 가장
Graph-based dependency parsers
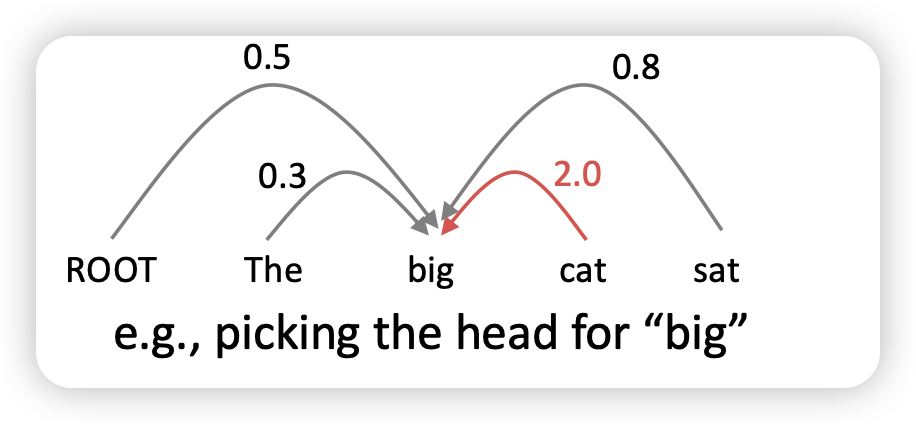
- binary arc (있고 없고) 가 아닌, score을 매긴 이후 가장 높은 점수가 높은 애를 서넞ㅇ
- 각각 단어들이 어떤 의미를 가지는지 contextual representations가 필요함
- 모든 관계를 확인해봐야하기에 계산량은 많긴함
- 근데 성능은 가장 좋음
교훈 지금은 모델 자체가 sequence자체를 이해하도록 알아서 만들었는데, 이전에는 문장을 구조화하기 위해서 정확하게 parsing하는 방법을들 연구했었음