Contextualized Word Embeddings
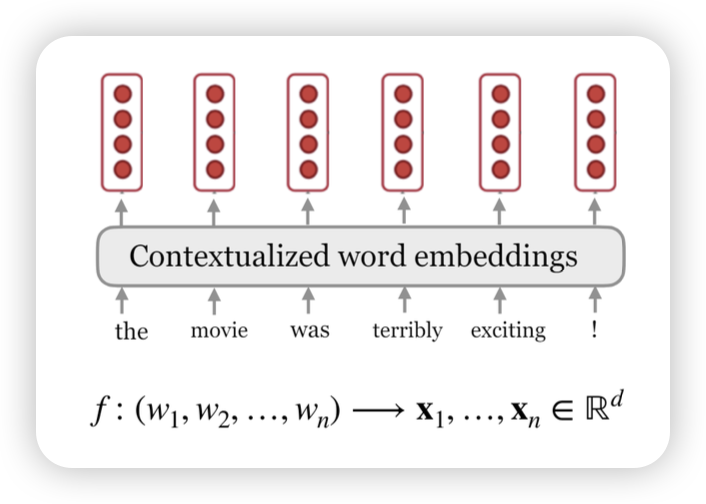
word2vec 만으로도 충분하지 않았나?
- 단순히 단어만으로만 의미를 표현하기엔 애매함
- 문맥에 따라 단어가 다른 의미로 사용

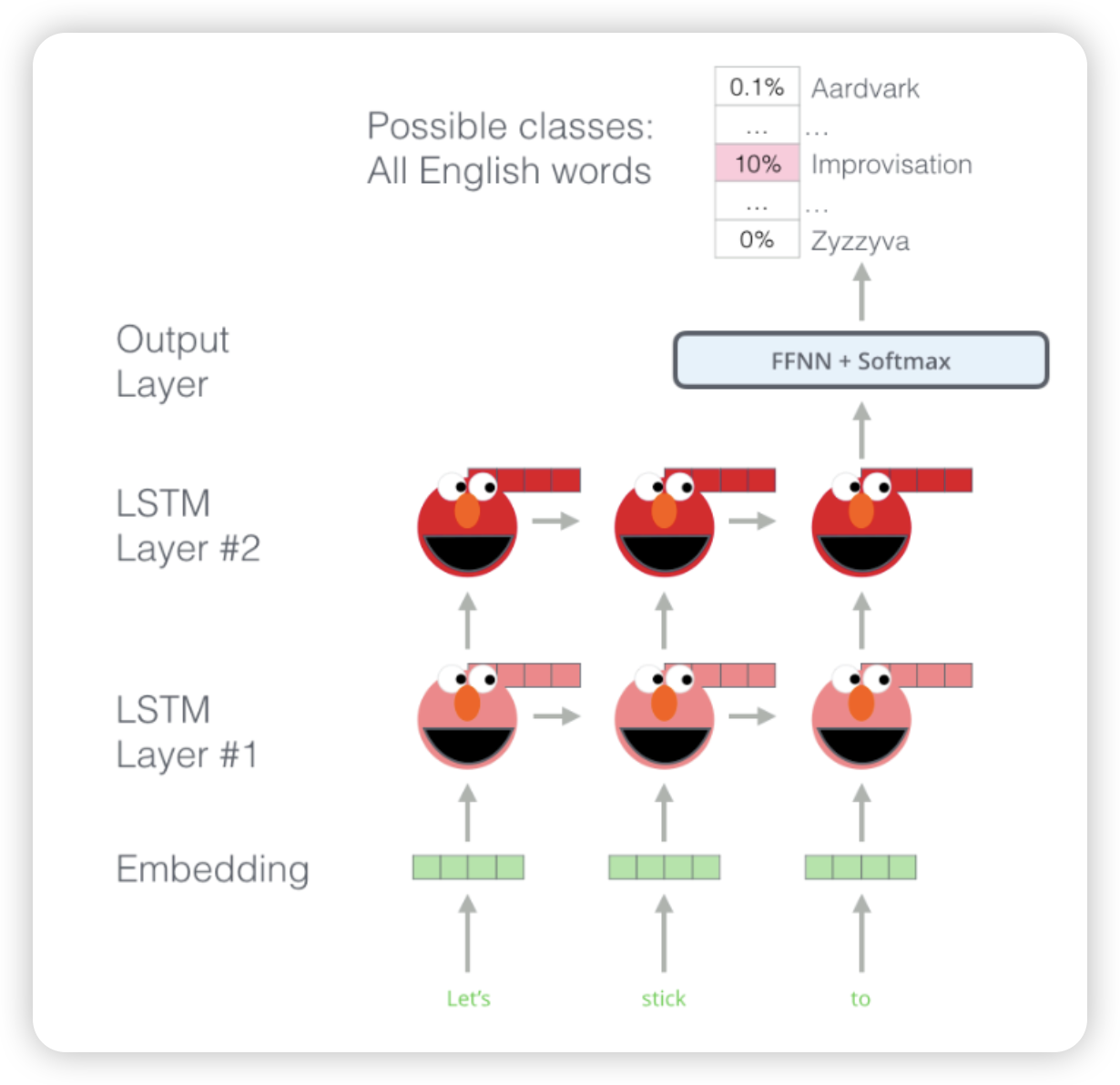
ELMo
Embeddings from Language Models
- LSTM based 언어 모델을 사용
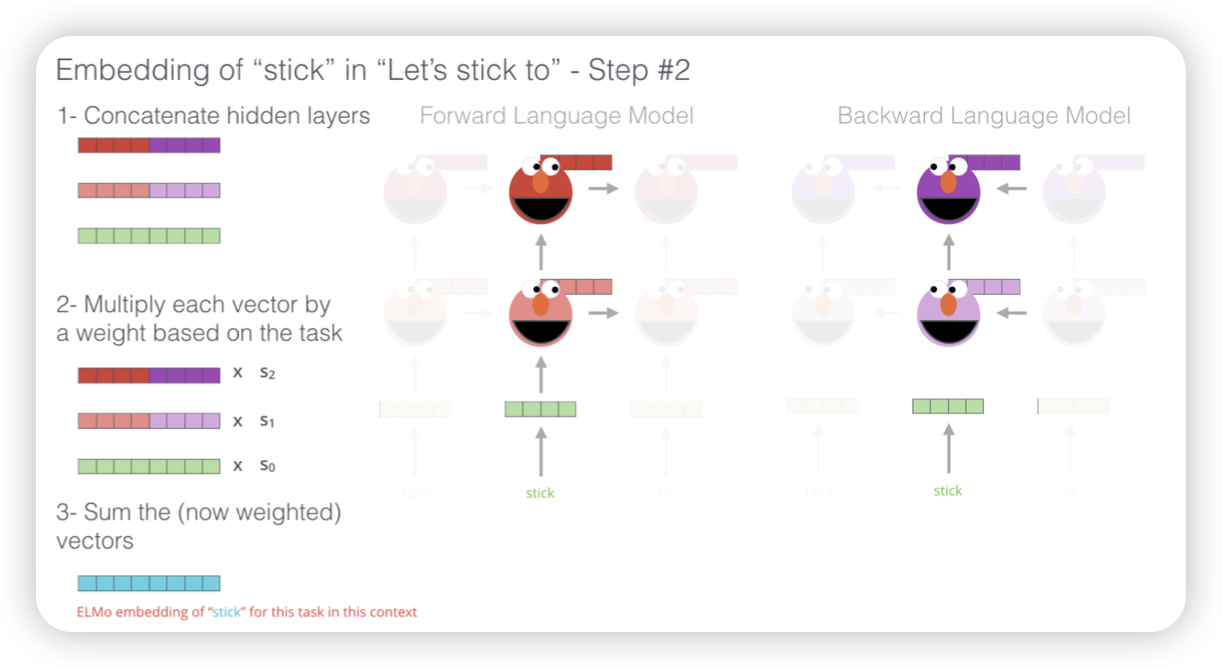
- forward, backward vector concat
- weighed sum (hyper-parameter)
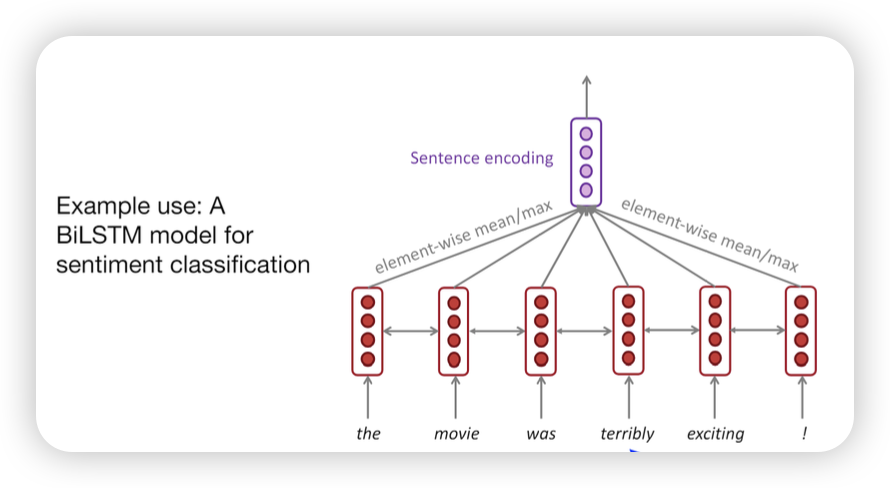
- 문맥을 같이 반영하니까 task를 잘 수행했다~
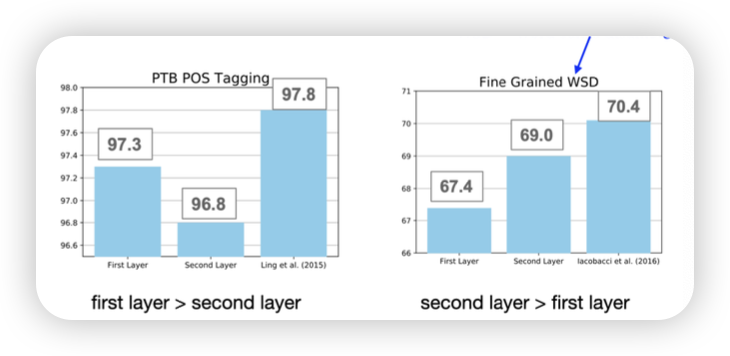
왜 bidirectional하게 썼을까?
왜 weighted sum을 할까?
- 각각의 다른 layer에서는 다른 정보들을 들고 있을 수 있기에 이걸 반영하기 위해?
- task마다 특정 layer의 성능이 달랐기에!
Pre-training
사전 학습! general한 지식을 학습한다!
새로운 corpus등을 가지고 학습을 시키는것
Finetuning
특정 task를 수행하기에, 미세조정을 시킴
왜 이런작업 중요해졌을까?
- 모델을 설계할 때, 학습만으로 모델을 성능을 평가하려고하면
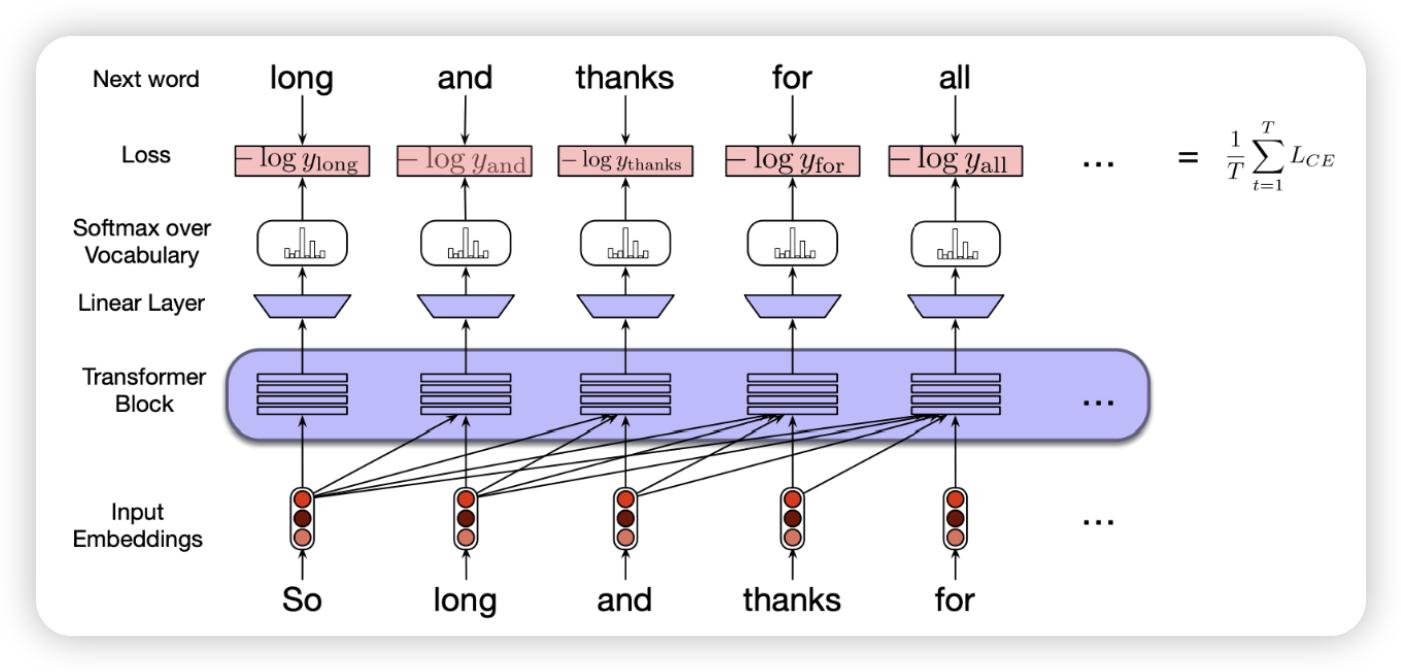
transformer 학습방법
네트워크 자체를 미세조정함
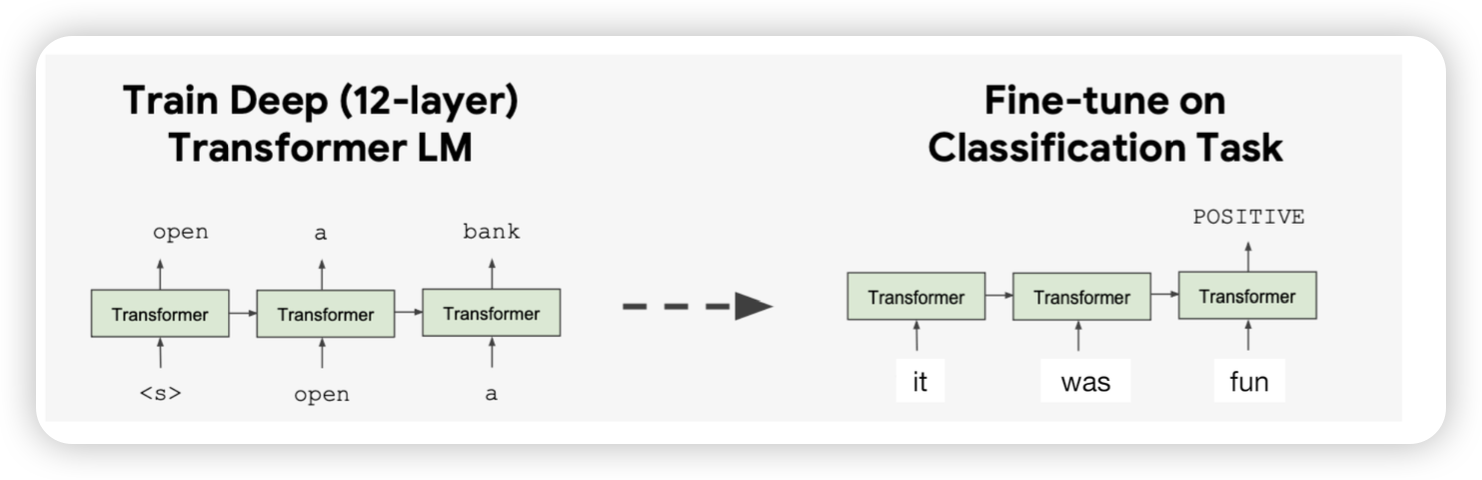
GPT
- lstm 대신에 transformer decoder 사용
- language 모델을 pretrain 대상으로 사용
- Trained on longer segments of text
-
사전학습된 GPT모델을 가지고 원하는 downstream 태스크에 맞춰서 finetunning
-
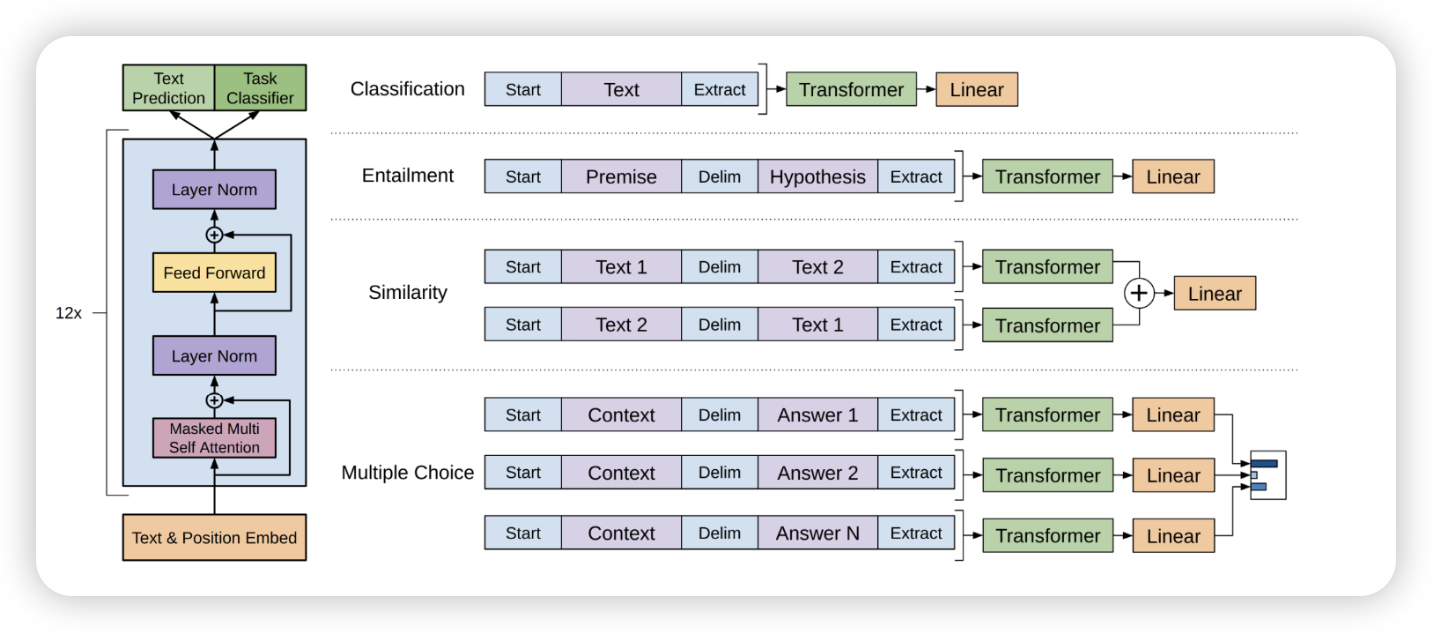
transformer block을 pretrain 시키고, task에 맞춰서 구조를 변경하자!
- cross encoder, bi encoder 같이?
-
새로운 pretrain 목표
- masked lanage modeling MLLM
- next sentence prediction NSP
MLLM

- 앞뒤 문장을 주고, 해당 구멍뚤린 단어를 맞춰봐
- LM은 앞에서부터 읽고 다음 단어를 맞춤
고려할거!
- 80-10-10 corruption
- 80퍼는 Mask를 뚫는다
- 10퍼는 랜덤한 단어로 변경함
- 10퍼는 그냥 둠
NSP
문장을 chunck하여 문맥을 이해할 수 있도록 함
CLS :문장의 처음을 나타냄 SEP: segment를 나누기 위함
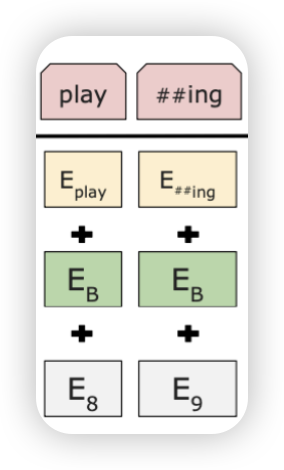
- ’##’ : 이렇게 단어를 쪼갤때도 특정 토큰을 사용하기도 함
- segment embedding 추가
- position + segment + token 이렇게 세개!
어떻게 학습시킬까?
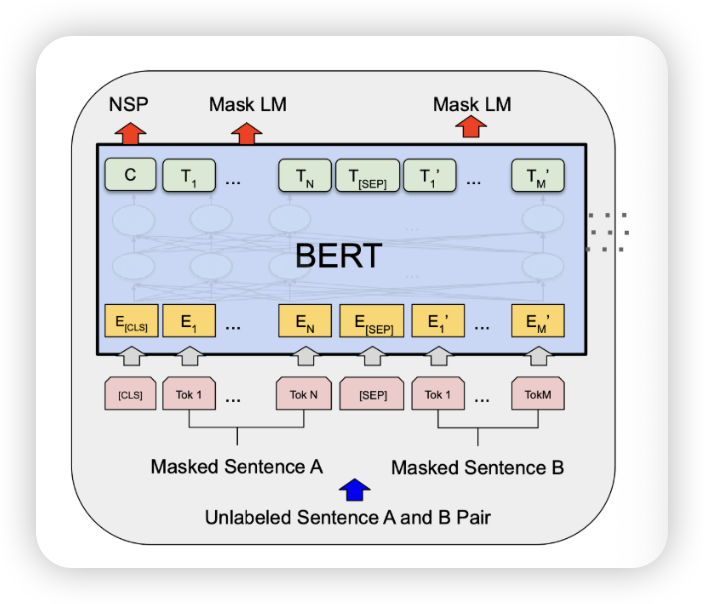
- 실제로는 같이 학습시킴!
- NSP, MLM 같이 함
- 원하는 태스크에 맞춰서 아키텍처를 갈아껴라